
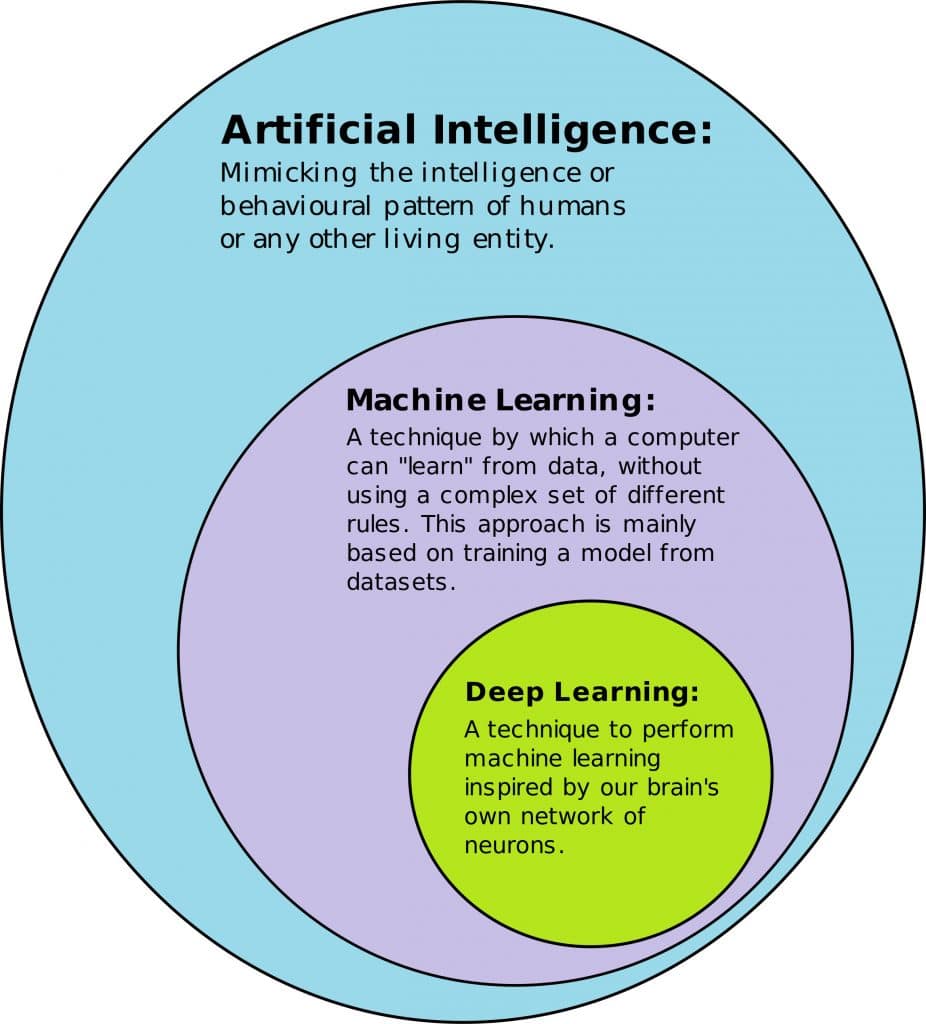
ডিপ লার্নিং সম্পর্কে জানার আগে জেনে নেই ইন্টিলিজেন্স কি। ইন্টিলিজেন্স হচ্ছে তথ্য প্রসেস করে একটা সিদ্ধান্তে পৌঁছানোর প্রক্রিয়া। মানুষ যা করে আরকি। আর মানুষের এই চিন্তা করে কোন সিদ্ধান্তে পৌঁছানোর কৃত্তিম রূপ হচ্ছে আর্টিফিশিয়াল ইন্টিলিজেন্স। মেশিন লার্নিং হচ্ছে আর্টিফিশিয়াল ইন্টিলিজেন্সের একটা শাখা।
মেশিন লার্নিং হচ্ছে উদাহরণ থেকে শেখা। আমরা মানুষেরা যে ভাবে শিখি, সেভাবে। সাধারণ প্রোগ্রামে আমরা স্পষ্ট ভাবে বলে দেই কি করতে হবে। মেশিন লার্নিংএ এই স্পষ্টভাবে বলে দেই না কি করতে হবে। কিছু ডেটা দেই, ডেটা থেকে প্রোগ্রাম নিজে নিজে চিন্তা করে আউটপুট দেয়। এই স্পষ্ট ভাবে ইন্সট্রাকশন না দেওয়া সত্বেও কোন প্রোগ্রামের চিন্তা করার ক্ষমতাই হচ্ছে মেশিন লার্নিং।
ডিপ লার্নিং
ডিপ লার্নিং হচ্ছে মেশিন লার্নিং এর একটি সাবফিল্ড যেখানে মেশিন লার্নিং এর জন্য নিউরাল নেট ব্যবহার করা হয়।
নিউরাল নেটোওয়ার্ক
আমাদের নার্ভ সিস্টেমের নিউরনকে অনুকরণ করে আর্টিফিশিয়াল নিউরনের উৎপত্তি। আর অনেক গুলো নিউরনের সমষ্টি হচ্ছে নিউরাল নেটওয়ার্ক। নিউরাল নেট ডেটা থেকে প্যাটার্ণ খুঁজে বের করে। এরপর পরবর্তী একই রকম নতুন ডেটা দিলে তার আউটপুট প্রিডিক্ট করতে পারে। এই তিনটার মধ্যে সম্পর্ক নিয়ে উইকিপিডিয়াতে সুন্দর একটি ইমেজ রয়েছেঃ
{kind=link}
সিঙ্গেল নিউরন
প্রতিটা নিউরন খুবি ছোট ছোট কম্পিউটেশন করে। যেমন একটা ইনপুট দিলে তা ছোট একটা ক্যালকুলেশন করে আরেকটা আউটপুট দেয়।

ইনপুটের সাথে নিউনের যে কানেকশন রয়েছে, তার একটা weight থাকে, যাকে আমরা বলতে পারি w। নিউরন মূলত শিখে এই ওয়েটের ভ্যালু পরিবর্তন করে। অনেক গুলো ডেটা দেওয়ার পর তাকে ট্রেইন করা হলে নিউরন নিজে নিজে এই ওয়েটের মান সেট করে নিতে পারে।
যেমন আমাদের এই নিউররনটি ইনিশিয়ালি ওয়েট ধরে নিচ্ছে 3। আর ইনপুট দিলাম 2। নিউরনের কাজ হচ্ছে ছোট্ট একটা ক্যালকুলেশন। ইনপুটকে এই ওয়েট দিয়ে গুন করতে হয়। তাহলে পাবো 2*3 মানে 6। মানে x এর মান 2 হলে y এর মান হবে 6। নিউরন এই ওয়েটের মান পরিবর্তন করে শিখে নেয় ইনপুটের পরিবর্তে আউটপুট কি দিবে। আমরা ইক্যুয়েশন পেয়েছি y = wx। y = mx এর সাথে আমরা পরিচিত। যা একটা সরল রেখার সমীকরণ।
y = wx সরল রেখাটা সর্বদা অরিজিন মানে (0,0) দিয়ে যাবে। আমাদের ডেটার প্যাটার্ণ যদি অক্ষের ডান অথবা বাম দিকে হয়, তাহলে এই ইকুয়েশন (মানে নিউরনটা) খুব একটা কাজে আসবে না। তো আমাদের সাথে একটা কনস্ট্যান্ট যুক্ত করতে হবে। যাকে আমরা বলি bias বা b। প্রতিটা নিউরনে একটা বায়াস যুক্ত করি আমরা। এটিও একটা ওয়েট, যেটাতে কোন ডেটা পাস করা হয় না।

তাহলে সমীকরণটি দাঁড়ালো 𝑦=𝑤𝑥+𝑏। প্রতিটা নিউরন ঠিক এতটুকু ক্যালকুলেশন করে। ইনপুট যা দেই, তার সাথে ওয়েট গুণ করে এবং বায়াস ভ্যালু যোগ করে আউটপুট দেয়।
সিঙ্গেল নিউরন দিয়েও আমরা মেশিন লার্নিং মডেল তৈরি করে ফেলতে পারি। যদিও আরো কিছু ধারণার দরকার হবে, তা আমরা একটু পরেই শিখব। এর আগে দেখে নেই কিভাবে একটা মাত্র নিউরন এবং একটা মাত্র ইনপুট দিয়েও একটা মেশিন লার্নিং মডেল তৈরি করে ফেলা যায়।
import tensorflow as tf
from tensorflow import keras
from keras import layers, models
import numpy as np
# training data
celsius_as_training_data = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
fahrenheit_as_labels = np.array([-40, 14, 32, 46.4, 59, 71.6, 100.4], dtype=float)
# model creation
model = keras.Sequential([
layers.Dense(units=1, input_shape=[1])
])
# model compilation
model.compile(loss='mean_squared_error',
optimizer=keras.optimizers.Adam(0.1))
# model training
model.fit(celsius_as_training_data, fahrenheit_as_labels, epochs=500, verbose=False)
print("Finished training the model")
# predict
# 𝑓=𝑐×1.8+32 || for 100, f = 212
print(model.predict(np.array([100.0])))
উপরের উদাহরণ সম্পর্কে বিস্তারিত একটা লেখা রয়েছে, তা দেখা যাবে এখানেঃ টেনসরফ্লো ব্যবহার করে নিউরাল নেটওয়ার্ক ট্রেনিং এবং প্রিডিকশন
একের অধিক ইনপুট
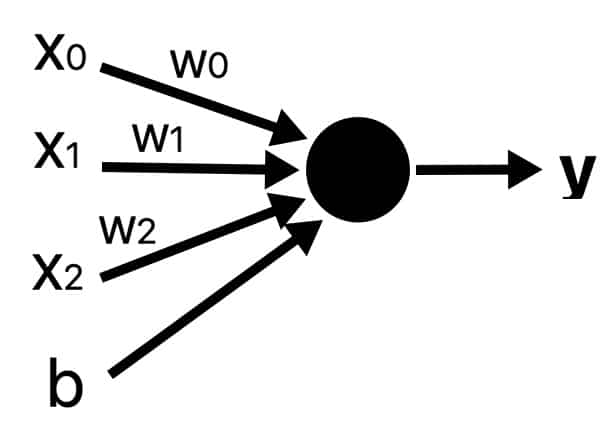
একটা নিউরনের একাধিক ইনপুট থাকতে পারে। তখন প্রতিটা ইনপুটকে এর নিউরনের সাথে কানেকটেড থাকা কানেকশন ভ্যালু দিয়ে গুন করে সব গুলো ইনপুট যোগ করে নেয়।
যেমন আমাদের নিউরনের যদি তিনটে ইনপুট পাস করি, তাহলে আউটপুট হবেঃ 𝑦=𝑤0𝑥0+𝑤1𝑥1+𝑤2𝑥2+𝑏। এভাবে একের অধিক ইনপুট হলে তা ক্যালকুলেট করবে।
লেয়ার
নিউরাল নেটওয়ার্কে সাধারণত নিউরন গুলো লেয়ার অনুযায়ী সাজানো থাকে। যেমন ইনপুট লেয়ার, আউটপুট লেয়ার, হিডেন লেয়ার ইত্যাদি। প্রতিটা নেটওয়ার্কে একের অধিক হিডেন লেয়ার থাকতে পারে। নিচের ছবিটা দেখিঃ

এখানে ইনপুট লেয়ার এবং আউটপুট লেয়ার ছাড়াও দুইটা হিডেন লেয়ার রয়েছে। হিডেন লেয়ারকে Dense লেয়ারও বলা হয়। এই লেয়ার গুলো সাধারণত ডেটা ট্রান্সফরমের এবং ডেটা থেকে ফিচার এক্সট্রাক্ট করার জন্য ব্যবহার করা হয়।
এক্টিভেশন ফাংশন
আমরা যে ডেটার উপর কাজ করব, কিছু কিছু ক্ষেত্রে আমাদের নন লিনিয়ার রিলেশনশিপ নিয়েও কাজ করতে হয়। আর নন লিনিয়ার রিলেশনশিপ ডেটার প্যাটার্ন বের করার জন্য দরকার এক্টিভেশন ফাংশন।
প্রতিটা লেয়ারের আউটপুটে একটা ফাংশন এপ্লাই করি, এটাই হচ্ছে এক্টিভেশন ফাংশন। কমন একটা ফাংশন হচ্ছে ReLU। rectified linear activation function বা ReLU খুবি সাধারণ একটা ফাংশন। যদি ইনপুট পজেটিভ হয়, তাহলে ইনপুটটাই রিটার্ণ করবে ওঠাব 0 রিটার্ণ করবে। ReLU ছাড়াও ভিন্ন ভিন্ন সমস্যার জন্য আরো অন্যান্য এক্টিভেশন ফাংশন রয়েছে।
লস ফাংশন
লস ফাংশনের কাজ হচ্ছে মডেল যে ভ্যালু প্রিডিক্ট করে এবং টার্গেট ভ্যালুর মর্ধ্যে পার্থক্য।
এক এক সমস্যার জন্য এক এক ধরনের লস ফাংশন ব্যবহার করতে হয়। যেমন রিগ্রেশন সম্পর্কিত সমস্যা গুলো সমাধান করার জন্য mean absolute error লস ফাংশন ব্যবহার করতে পারি আমরা।
অপটিমাইজার
আমরা জেনেছি নিউরালনেট কোন কিছু শিখে নেয় তার ওয়েট গুলো পরিবর্তন করে। এই ওয়েট পরিবর্তনের কাজ করে অপটিমাইজার অ্যালগোরিদম গুলো। লক্ষ্য থাকে লস কমানো। ডীপ লার্নিং এর এই অপটিমাইজেশন অ্যালগরিদম গুলো প্রায় সব গুলোই stochastic gradient descent ফ্যামিলির মধ্যে পড়ে। এই অ্যালগোরিদম গুলো নিউরালনেটের ট্রেইনিং এর প্রতিটা স্টেপে কাজ করে। প্রতিটা স্টেপে অপটিমাইজেশন অ্যালগরিদম যে কাজ গুলো করেঃ
- প্রিডিকশন পাওয়ার জন্য ট্রেনিং ডেটা পাস করে
- প্রিডিকশন পাওয়ার পর লস ফাংশন ব্যবহার করে প্রিডিক্টেড ভ্যালু এবং টার্গেট ভ্যালু থেকে লস বের করে।
- লস কমানোর জন্য ওয়েট ভ্যালু গুলো পরিবর্তন করে।
- স্টেপ এক থেকে তিন পর্যন্ত বার বার রান করা হয়, যতক্ষণ পর্যন্ত না লস মিনিমাল হয়।
ব্যাচ সাইজ
প্রতিবার যে কয়টা ট্রেইন ডেটা নিয়ে মডেল ট্রেইন করা হয়, তাই ব্যাচ সাইজ।
ইপক / Epoch
সব গুলো ট্রেনিং ডেটা নিয়ে একবার ট্রেনিং শেষ করাকে বলে একটা ইপক। ইপক নাম্বার যত হবে, ততবার ট্রেইন ডেটার উপর মডেল ট্রেইন হবে।
উপরের টপিক্স গুলোর থিওরিই আলোচনা করা হয়েছে। ব্যাকগ্রাউন্ডে কিভাবে কাজ করে, ম্যাথম্যাটিক্যালি কিভাবে কাজ করে, সেগুলো আলোচনা করা হয়নি। সাধারণত থিউরিটাই দরকার হয়। কারণ নিউরন, লস ফাংশন, অপটিমাইজার ইত্যাদির কোড আমরা লিখি না। মেশিন লার্নিং এর অনেক গুলো লাইব্রেরি রয়েছে, যেগুলোতে কোড গুলো করা আছে। আমরা শুধু ব্যবহার করি। কোড না করলেও থিউরি জানা না থাকলে আমরা বুঝতে পারব না কোনটার কাজ কি, কোন কোডটা কেন লেখা হয়েছে ইত্যাদি।
আমরা এতক্ষণ পর্যন্ত যা জেনেছি, এগুলো ব্যবহার করে একটা মডেল ট্রেইন করি। এর জন্য আমরা Heart Attack Analysis & Prediction Dataset ব্যবহার করব। প্রথমে ডেটাসেটটি ডাউনলোড করে নিব। ক্যাগেলের এই ডেটাসেটের পেইজ থেকে Data ট্যাবে ক্লিক করে ডেটা গুলো ডাউনলোড করে নিতে পারবেন।
ক্যাগেলেই আমরা চাইলে কোড লিখে রান করে দেখতে পারি। আমি গুগল কোল্যাব ব্যবহার করছি।
কোল্যাবে একটা নোটবুক ওপেন করে নিন। এরপর প্রথমে ডেটা আপলোড করে নিন।
তার জন্য কোল্যাবের ফাইল আইকনে ক্লিক করুন। এরপর ঐখানে ফাইল আপলোড করার অপশন পাবেন। এরপর ডেটাসেটটি আপলোড করে নিন। ফাইল থেকে ডেটাসেট রিড করতেঃ
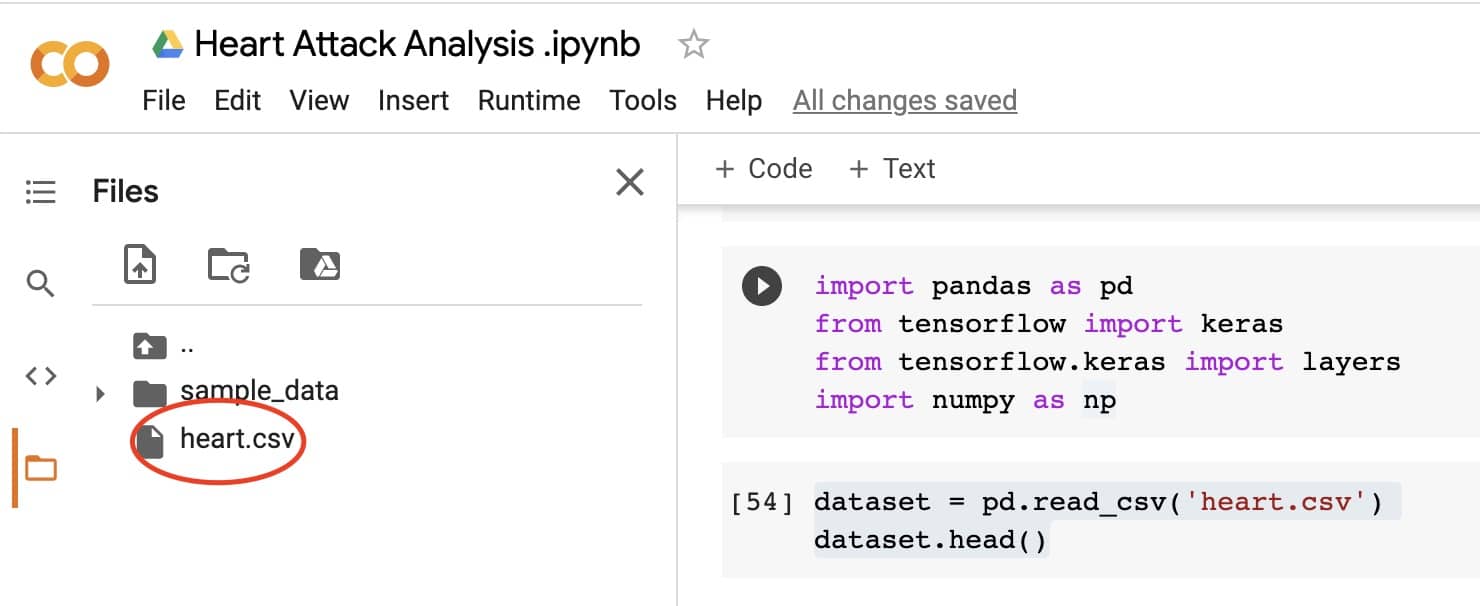
# reading data from file
dataset = pd.read_csv('heart.csv')
সব কিছু ঠিক থাকলে ডেটা ইনফো দেখে নিতে পারেনঃ
# get dataset info
dataset.info()
ডেটাসেট ইনফো দেখলে দেখতে পাবেন এখানে মোট ১৪টা কলাম রয়েছে। আউটপুট কলামটা হচ্ছে টার্গেট ভ্যালু। মডেল ট্রেইন করার জন্য ট্রেনিং ডেটা থেকে এই টার্গেট কলামটা রিমুভ করে নিতে হবে।
# labels or target value
labels = dataset['output']
# removing target data from training data
training_data = dataset.drop(columns=[‘output'])
# get training data info
training_data.info()
ট্রেনিং ডেটার ইনফো দেখলে আমরা দেখব মোট কলাম রয়েছে ১৩টা। আউটপুট কলামটা আমরা রিমুভ করে নিয়েছি।
সাধারণ মেশিন লার্নিং প্রজেক্ট গুলো দেখলে দেখে থাকবেন যে ডেটা গুলো ট্রেইনিং সেট এবং টেস্ট সেটে ভাগ করা থাকে বা ভাগ করে নেয়। সাধারণ X_train, X_test, y_train, y_test এভাবে লেখা থাকে আরকি। সিমপ্লিসিটির জন্য আমরা পুরা ডেটাকেই ট্রেইনিং ডেটা হিসেবে ব্যবহার করব। আর এই জন্য প্রথমে আমরা একটা মডেল তৈরি করে নেইঃ
# creating model
model = keras.Sequential([
layers.Dense(256, activation='relu', input_shape=[13]),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
এখানে input_shape=[13] হচ্ছে ইনপুট হিসেবে কয়টা ডেটা দিচ্ছি। আমাদের ট্রেইনিং ডেটাতে মোট কলাম [ফিচার] রয়েছে ১৩টা, তাই input_shape হিসেবে ১৩ দিচ্ছি। এটা ডাইনামিক্যালিও করা যেত, সিপ্লিসিটির এভাবে লিখলাম।
এরপর মডেল কম্পাইল এবং ট্রেইন করে নিতে পারি। ট্রেইন করার সময় আমরা দেখব কিভাবে আস্তে আস্তে মডেলের লস কমে আসছে। লস ডেটার প্লট করলেই ভিজ্যুয়ালি দেখতে পাবো। সম্পূর্ণ কোডঃ
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from keras import layers, models
import numpy as np
# reading data from file
dataset = pd.read_csv('heart.csv')
# get dataset info
dataset.info()
# more about dataset
dataset.describe()
# first few items from dataset
dataset.head()
# labels or taret value
labels = dataset['output']
# removing target data from training data
training_data = dataset.drop(columns=['output'])
# creating model
model = keras.Sequential([
layers.Dense(256, activation='relu', input_shape=[13]),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
# model compile
model.compile(loss='mae', optimizer='adam')
# model training
history = model.fit(training_data, labels, epochs=50, batch_size=128)
# plotting loss history
history_df = pd.DataFrame(history.history)
history_df['loss'].plot();
উপরের উদাহরণের নোটবুক । নিজে নিজে ট্রাই করার সময় কোড গুলো নোটবুকের আলাদা আলাদা সেলে লিখলে প্রতিটা সেল আলাদা আলাদা ভাবে রান করলে ডিপ লার্নিং সম্পর্কে বুঝতে সুবিধে হবে।
ক্যাগেল ডেটাসেটের পেইজে গেলে কোড নামে একটা ট্যাব রয়েছে। ঐ ট্যাবে গেলে অনেক গুলো কোড পেয়ে যাবো। কিছু কিছু কোড টিউটোরিয়াল সহ অনেক ডিটেইলস ভাবে লেখা থাকে। আবার ফিল্টার থেকে স্পেসিফিক ল্যাঙ্গুয়েজের কোডও খুঁজে বের করা যায়। যেমন আমি চাইলে টেনসোরফ্লো এর কোড ফিল্টার করে নিতে পারি, সহজে খুঁজে পাওয়ার জন্য। এভাবে ডিপ লার্নিং রিলেটেড প্রজেক্ট গুলো দেখে অনেক কিছু শিখে নিতে পারবেন।
ক্যাগেলে অনেক গুলো ডেটাসেট রয়েছে। এই ডেটাসেট গুলো নিয়ে নিজে নিজে প্র্যাকটিস কলে অনেক সহজে শিখা যাবে। অন্যরা কিভাবে কোড লিখে, কিভাবে চিন্তা করে, কিভাবে একটা সমস্যা সমাধান করতে হয়, তাও জানা যাবে কোড দেখে দেখে। ক্যাগেলের ডেটাসেট ট্যাবে অনেক গুলো পাবলিক ডেটা রয়েছে, সেগুলো প্র্যাকটিস করতে পারেন।
এই টিউটোরিয়ালে আমরা ডিপ লার্নিং এর ব্যাসিক কিছু ধারণা পেয়েছি। যা শুরু করার জন্য যথেষ্ট। এরপরের পোস্টে ইনশাহ আল্লাহ আমরা ওভারফিটিং & আন্ডারফিটিং, ড্রপআউট, ট্রান্সফার লার্নিং ইত্যাদি জানার চেষ্টা করব।
এই ব্লগের আর্টিফিশিয়াল ইন্টিলিজেন্স এবং মেশিন লার্নিং নিয়ে সব গুলো লেখা পাওয়া যাবে এখানে।