
আমরা একটা মেশিন লার্নিং প্রজেক্ট করব যার আউটপুট ক্যাগেল কম্পিটিশনে সাবমিট করতে পারব। তার আগে ব্যাসিক কিছু ধারণা নিয়ে নেই। এছাড়া আর্টিফিশিয়াল ইন্টিলিজেন্স এবং মেশিন লার্নিং নিয়ে এই ব্লগে অনেক গুলো লেখা রয়েছে। সেগুলো পড়লে দরকারি ধারণা গুলো পাওয়া যাবে।
ডিসিশন ট্রিঃ
ফ্লো চার্টের কথা মনে আছে? কোন একটা সিদ্ধান্তে পৌঁছানোর বিভিন্ন ধাপ হচ্ছে ফ্লো চার্ট। যেমন দুইটা সংখ্যা থেকে বড় সংখ্যাটা বের করার জন্য যদি ফ্লো চার্ট আঁকি, তাহলে তা হবে নিন্মরুপঃ
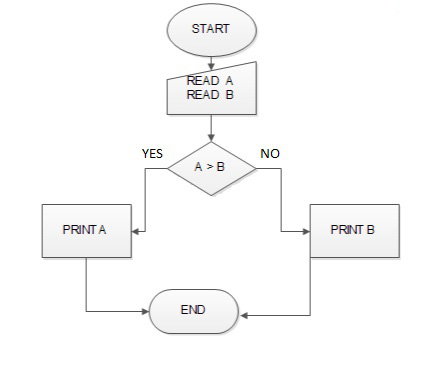
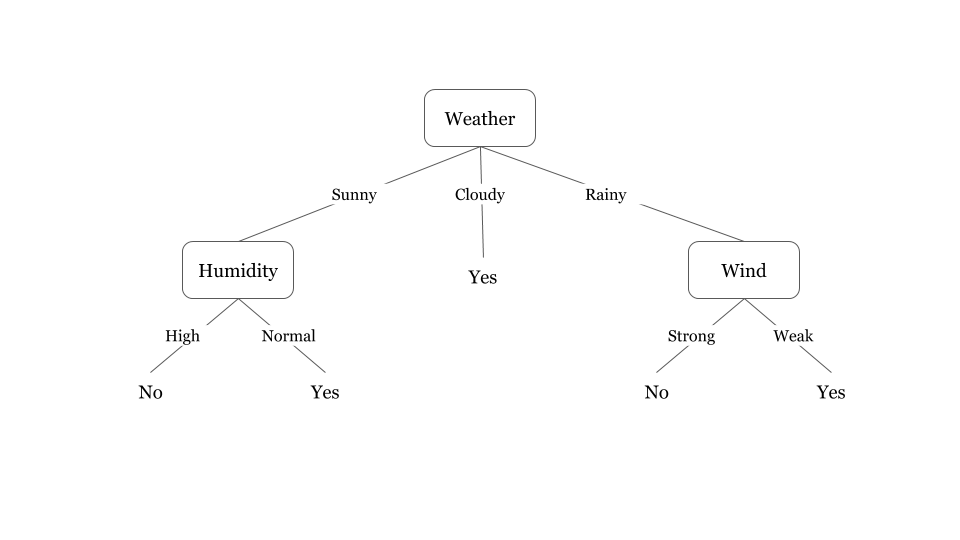
ডিসিশন ট্রি ফ্লো চার্টের মতই। যে কোন ডেটাকে বিভিন্ন প্রশ্ন করে কোন সিদ্ধান্তে পোঁছানোই এই ডিসিশন ট্রি এর কাজ। প্রধান পার্থক্য হচ্ছে ফ্লো চার্ট কোন নির্দিষ্ট প্যাটার্ণ মানে না কিন্তু ডিসিশন ট্রি প্যাটার্ণ মানে। যেমন নিচের ডিসিশন ট্রি টা দেখতে পারি, যেখানে আবহাওয়ার ডেটাকে বিভিন্ন প্রশ্নের ভিত্তিতে ভাগ করা হয়েছে। এখন এই ট্রি থেকে যে কোন উত্তর সহজেই খুঁজে পাওয়া যাবে।
র্যান্ডম ফরেস্ট
ডিসিশন ট্রি সব গুলো ডেটাকে একটা ট্রিতে সাজায়। র্যান্ডম ফরেস্ট র্যান্ডমলি কিছু ট্রি তৈরি করে। এরপর যে ট্রিতা বেস্ট রেজাল্ট দেয়, তাই সিলেক্ট করে। আমরা আমাদের এই প্রজেক্টে র্যান্ডম ফরেস্ট ক্লাসিফায়ার ব্যবহার করব।
ডেটা – যার উপর আমরা মেশিন লার্নিং প্রয়োগ করব
প্রায় সব গুলো মেশিন লার্নিং এ উদাহরণ হিসেবে টাইটানিক ডেটাসেট ব্যবহার করা হয়। আমি ভেবেছি অন্য কোন ডেটাসেট ব্যবহার করব। পরে অনেক চিন্তা ভাবনা করে দেখলাম এটা দিয়ে শুরু করাই উত্তম হবে। ছোট ডেটাসেট, অল্প কয়েকটা কলাম, সহজেই বুঝা যাবে। কতটুকু শিখলাম, তা টেস্ট করার জন্য ক্যাগেলে গিয়ে Titanic: Machine Learning from Disaster কন্টেস্টে গিয়ে টেস্ট করা যাবে। ক্যাগেল সম্পর্কে একটা আইডিয়া হবে ইত্যাদি ইত্যাদি।
সবার আগে ডেটাসেট সম্পর্কে ধারণা নিয়ে নিলে লেখাটি বুঝতে সুবিধে হবে। টাইটানিক কন্টেস্টের ডেটা পেইজে গিয়ে Download All এ ক্লিক করে সব গুলো ডেটা ডাউনলোড করে নিন। এরপর train.csv ফাইলটা এক্সেল বা Google Sheet বা অন্য কোন ভাবে ওপেন করে বুঝার চেষ্টা করুন।
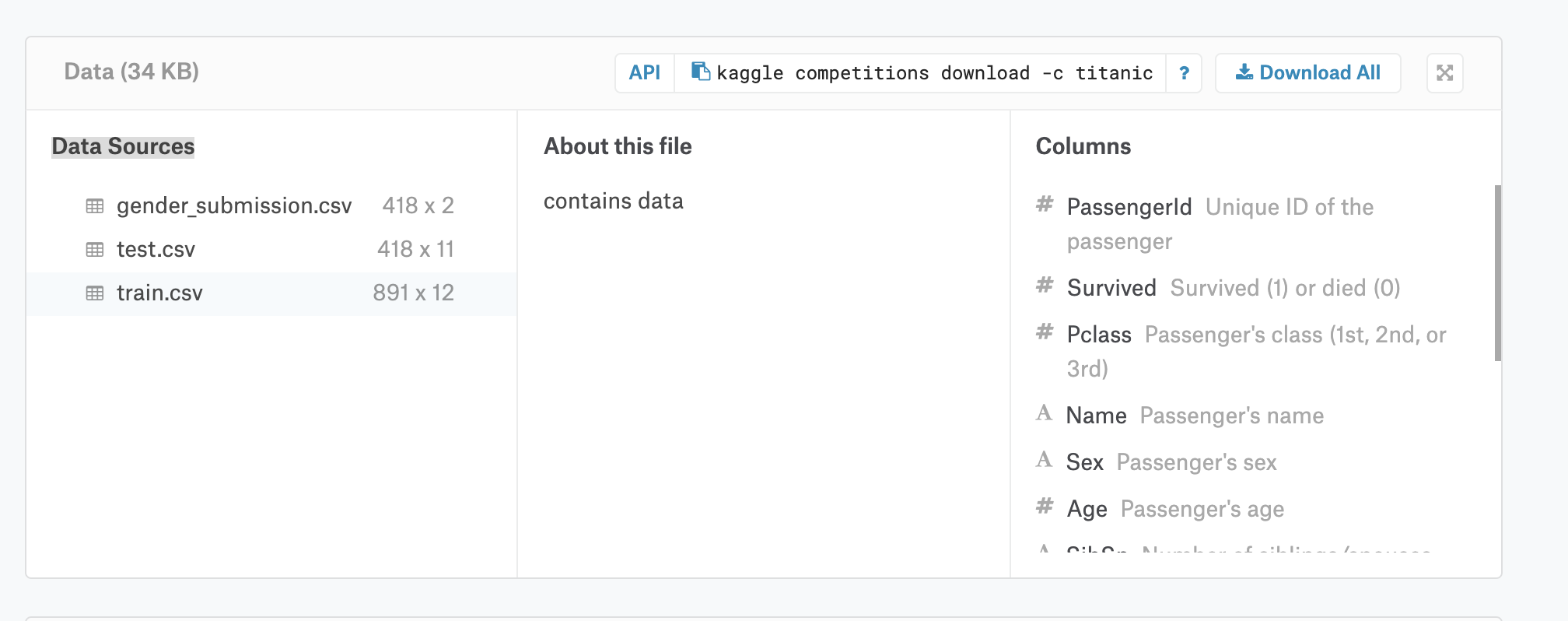
এখানে আমাদের লক্ষ্য সম্পর্কে একটু বলি। আমরা সবাই জানি টাইটানিক ডুবে গিয়েছে। অনেক মানুষ মারা গিয়েছে। এখন প্যাসেঞ্জার ডেটা এনালাইসিস করে আমাদের বের করতে হবে কার ডুবে যাওয়ার সম্ভাবনা কতটুকু। মানে কে কে ডুবে গিয়েছে, তা বের করাই হচ্ছে আমাদের কাজ।
ওয়ার্কস্টেশন
আমরা লোকাল মেশিনে পাইচার্মে আমাদের কোড গুলো লিখব। আপনি চাইলে ক্যাগেলের নোটবুক, গুগল কোল্যাব বা অন্য কোথাও লিখতে পারেন।
ধরে নিচ্ছি আপনি পাইচার্ম ও Anaconda ইন্সটল করে নিয়েছেন। Anaconda ছাড়াও আপনি চাইলে দরকারি প্যাকেজ গুলো আলাধা আলাধা ইন্সটল করে নিতে পারেন। তবে মেশিন লার্নিং এর জন্য দরকারি প্যাকেজ গুলো Anaconda ইন্সটল করে দিবে। তাই শুরুতে Anaconda ইন্সটল করে নিলেই সব কিছু বুঝতে সুবিধে হবে।
পাইচার্মে একটা প্রজেক্ট তৈরি করে নিব। এরপর একটা ডিরেক্টরি তৈরি করে সেখানে test.csv এবং train.csv ডেটা গুলো রাখব। এরপর একটা পাইথন পাইল তৈরি করে নিব। এবার আমরা আমাদের প্রথম মেশিন লার্নিং প্রজেক্ট তৈরি করতে প্রস্তুত।
ডাটা সম্পর্কে পরিচিত
সবার আগে আমরা ডেটা লোড করে নিব। ডেটা এক্সপ্লোরেশনের জন্য পান্ডা জনপ্রিয় একটা লাইব্রেরি। তার জন্য আমরা পান্ডা ইম্পোর্ট করে নিব।
train_data = pd.read_csv("data/train.csv")
ডেটা লোড করার পর আমরা ডেটা সম্পর্কে জানতে প্রস্তুত। যেমন প্রথম কয়েকটা রো যদি আমরা দেখি, তাহলে আমরা বুঝতে পারব কি কি ডেটা রয়েছেঃ
print(train_data.head())
আরেকটু বিস্তারিত যদি জানতে চাই, তাহলে লিখবঃ
print(train_data.describe())
তাহলে প্রতিটা কলামে কয়টা আইটেম রয়েছে, এভারেজ সহ অন্যান্য ডেটা দেখাবে।
ধরে নিচ্ছি ডেটা সম্পর্কে আমরা বুঝতে পেরেছি। আমাদে লক্ষ্য হচ্ছে একটা মেশিন লার্নিং মডেল তৈরি করা, যা আমাদের বলে দিতে পারবে কে বেঁচে থাকবে, কে থাকবে না।
মেশিন লার্নিং মডেল ও ফিচার সিলেকশন
আমরা জানি টাইটানিক যখন ডুবে যায়, তখন বেশির ভাগ পুরুষেরাই মারা যায়। কারণ যে ছোট ছোট বোট গুলো ছিল, সেগুলোতে মহিলা এবং শিশুদের অগ্রাদিকার দেওয়া হয়।
এখন আমরা সহজেই বলতে পারি যারা পুরুষ, তারা মারা যাবে। আর যারা মহিলা, তারা বেঁচে থাকবে। অর্থাৎ সেক্স অনেক ইম্পোর্টেন্ট ফিচার এই ডেটার জন্য।
আবার যারা শিশু তারাও অগ্রাদিকার পেয়েছিল ছোট বোট গুলোতে উঠার ক্ষেত্রে। এখন সেক্স Male এর ক্ষেত্রে বয়স ও ইম্পোর্টেন্ট। যাদের বয়স ধরি ১৮ বছরের কম, তাদের বেঁচে থাকার পসিবিলিটি বেশি। তাহলে বয়স ও ইম্পোর্টেন্ট একটা ফিচার।
আমাদের রেজাল্ট এর জন্য যে সব ফিচার গুলো ইম্পোর্টেন্ট, তা সিলেক্ট করাকে বলা হয় ফিচার সিলেকশন। এই ফিচার সিলেকশন অনেক গুরুত্বপূর্ণ। যেমন যদি আমরা ভুল ফিচার (age, sex..)গুলো নেই, তাহলে হয়তো আমাদের মডেল ভুল রেজাল্ট দিবে। তাই আমাদের ভাবতে হবে কি কি ফিচার গুলো নিতে হবে মেশিন লার্নিং মডেলের জন্য।
আমরা যদি জানতে চাই কি কি ফিচার/কলাম রয়েছে আমাদের ডেটাতে, তাহলে এভাবে দেখতে পারি।
print(train_data.columns)
যা প্রিন্ট করবেঃ [‘PassengerId’, ‘Survived’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’,
‘Parch’, ‘Ticket’, ‘Fare’, ‘Cabin’, ‘Embarked’]
ডেটা একটু এনালাইসিস করে ধরে নিচ্ছি প্রিডিকশনের জন্য আমাদের এই ফিচার গুলো লাগবে শুধুঃ
features = ["Pclass", "Sex", "SibSp", "Parch"]
এই ফিচার গুলো নিয়েই আমরা আমাদের মডেলকে ট্রেইন করব। পরে ইচ্ছে করলে আমরা ফিচার বাড়িয়ে আমাদের মডেল ট্রেইন করাতে পারব।
তাই পুরো train_data থেকে আমাদের দরকারি ডেটা গুলো নিতে পারি এভাবেঃ
X = train_data[features]
ট্রেইনিং টার্গেট
আমাদের train_data তে একটা কলাম আছে Survived নামে।
এটা হচ্ছে আমাদের প্রিডিকশন টার্গেট। এই টার্গেট ডেটাকে আলাদা করে নিবঃ
y = train_data[‘Survived’]
মডেল তৈরি ও ক্লাসিফায়ার সিলেকশন
অনেক গুলো মেশিন লার্নিং ক্লাসিফায়ার রয়েছে। আমরা যেহেতু অলরেডি ডিসিশন ট্রি সম্পর্কে জানি, তাই ডিসিশন ট্রি ক্লাসিফায়ার ব্যবহার করব।
তার জন্য প্রথমে ডিসিশন ট্রি ক্লাসিফায়ার ইম্পোর্ট করে নিবঃ
from sklearn.ensemble import RandomForestClassifier
তারপরের কাজ হচ্ছে ক্লাসিফায়ারটা সিলেক্ট করাঃ
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
এরপরের কাজ হচ্ছে fit। এটা করে কি, আমরা যে ডেটা দেই, তার মধ্যে একটা প্যাটার্ণ খুঁজে বের করে। যাকে বলে মডেল ট্রেইন করা।
model.fit(X, y)
মডেল ট্রেইন করা শেষে আমরা এবার প্রিডিক্ট করতে প্রস্তুত।
আমরা প্রিডিক্ট করব হচ্ছে টেস্ট ডেটার উপর। তার জন্য ট্রেইন ডেটার মত টেস্ট ডেটাও লোড করে নিব। মনে রাখতে হবে যে যে ফিচার নিয়ে আমরা আমাদের মডেল লোড করেছি, ঠিক সেই ফিচার নিয়েই প্রিডিক্ট করতে হবে।
টেস্ট ডেটা লোড এবং টেস্ট ডেটার ফিচার সিলেকশনঃ
test_data = pd.read_csv("data/test.csv")
X_test = pd.get_dummies(test_data[features])
প্রিডিক্ট করতেঃ
আমরা আমাদের মডেলকে ট্রেইন করেছি। এখন কে কে বেঁচে থাকবে, কে কে মারা যাবে, তা প্রিডিক্ট করতে পারব।
predictions = model.predict(X_test)
এখন যদি প্রিডিকশন প্রিন্ট করি, তাহলে দেখব আমাদের মডেল বলে দিয়েছে কে কে বেঁচে থাকবে, কে কে মারা যাবে।
print(predictions)
এখানে 0 মানে মারা যাবে এবং 1 মানে বেঁচে থাকবে। এখন আমাদের এই প্রিডিকশন ক্যাগেল কম্পিটিশনে আপলোড করার জন্য প্রস্তুত। তার আগে দেখে নেই আমাদের কি কি কাজ করতে হয়েছে আমাদের প্রথম মেশিন লার্নিং প্রজেক্ট তৈরি করতেঃ
- ডাটা লোড করা
- ফিচার সিলেক্ট করা
- মডেল সিলেক্ট করা
- মডেল ফিট বা ট্রেইন করা
- প্রিডিক্ট করা বা টেস্ট করা
যত কমপ্লিকেটেড মেশিন লার্নিং প্রজেক্টই হোক না কেন, সব গুলোর মূল কাজ এই স্টেপ গুলোই। এই সিম্পল প্রজেক্টের স্টেপ গুলো যদি ভাল করে বুঝতে পারি, আমরা যে কোন কমপ্লেক্স প্রজেক্ট বুঝতে পারব সহজেই।
ক্যাগেল কম্পিটিশন
Kaggle কে মেশিন লার্নিং এবং ডেটা সাইন্সের এর একটা কমিউনিটি বলা যায়। এখানে মেশিন লার্নিং এবং ডেটা সাইন্স শেখার পাশা পাশি কতটুকু শেখা হয়েছে, তা টেস্ট করা যায়। এবং ফাইনালি বিভিন্ন কম্পিটিশনে যোগ দিয়ে বড় এমাউন্টের টাকা এওয়ার্ড পাওয়া যায়। কম্পিটিশন কিভাবে করতে হয়, তাই আমরা এখন শিখব।
প্রথমে ক্যাগেলে একটা একাউন্ট খুলে নিব। একটু আগে আমরা যে ডেটা সেট নিয়ে কাজ করেছি, তাও একটা কম্পিটিশনের ডেটা। Titanic: Machine Learning from Disaster নামক কম্পিটিশন। এই কম্পিটিশন মূলত শেখার কাজে ব্যবহার করা হচ্ছে। সত্যিকারের কম্পিটিশন গুলো দেখা যাবে কম্পিটিশন পেইজে ।
কোন কম্পিটিশনে যোগ দিতে চাইলে ঐ কম্পিটিশনের পেইজে গিয়ে Join Competition এ ক্লিক করে জয়েন করা যাবে। এরপর আউটপুট সাবমিট করতে পারব। সাবমিট করার পর ঐ ডেটা এনালাইসিস করে লেডারবোর্ডে দেখাবে কত তম হয়েছি।
এক এক কম্পিটিশনের নিয়ম এক এক রকম। তাই কোন কম্পিটিশনে যোগ দিতে চাইলে তা সম্পর্কে ভালো ভাবে পড়ে নেওয়া দরকার। টাইটানিক কম্পিটিশনে সাবমিট করতে হবে কে কে বেঁচে যাবে, কে কে মারা যাবে সে ডেটা। CSV ফরমেটে। সাবমিট ডেটা কেমন হবে, তা আমরা জানতে পারব Data ট্যাব থেকে, এরপর gender_submission.csv নামে একটা ফাইল দেখব। এটিই হচ্ছে স্যাম্পল সাবমিশন ডেটা। যেখানে রয়েছে দুইটা কলাম। একটা হচ্ছে PassengerId এবং আরেকটা হচ্ছে Survived।
আমরা যে প্রিডিকশন করেছি, তা এভার CSV ফরমেটে আউটপুট দিবঃ
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
এই পর্যন্ত আমরা যা লিখেছি, সব গুলো এক সাথে, মেশিন লার্নিং ব্যবহার করে প্রিডিকশন তৈরি করতে মাত্র এই কয়টা লাইন লিখতে হয়! সহজ না?
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# load data
train_data = pd.read_csv("data/train.csv")
test_data = pd.read_csv("data/test.csv")
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
y = train_data['Survived']
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
# testing
X_test = pd.get_dummies(test_data[features])
predictions = model.predict(X_test)
# generate CSV
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print('csv generated.')
আমরা দেখব আমাদের জন্য my_submission.csv নামে একটা ফাইল তৈরি হয়েছে। এই ফালটি আমরা ক্যাগেলে সাবমিট করতে পারব। সাবমিট করার জন্য কম্পিটিশন পেইজে গিয়ে Submit Predictions এ ক্লিক করব। এরপর ফাইলটি সিলেক্ট করে নিচে গিয়ে Make Submission এ ক্লিক করব।
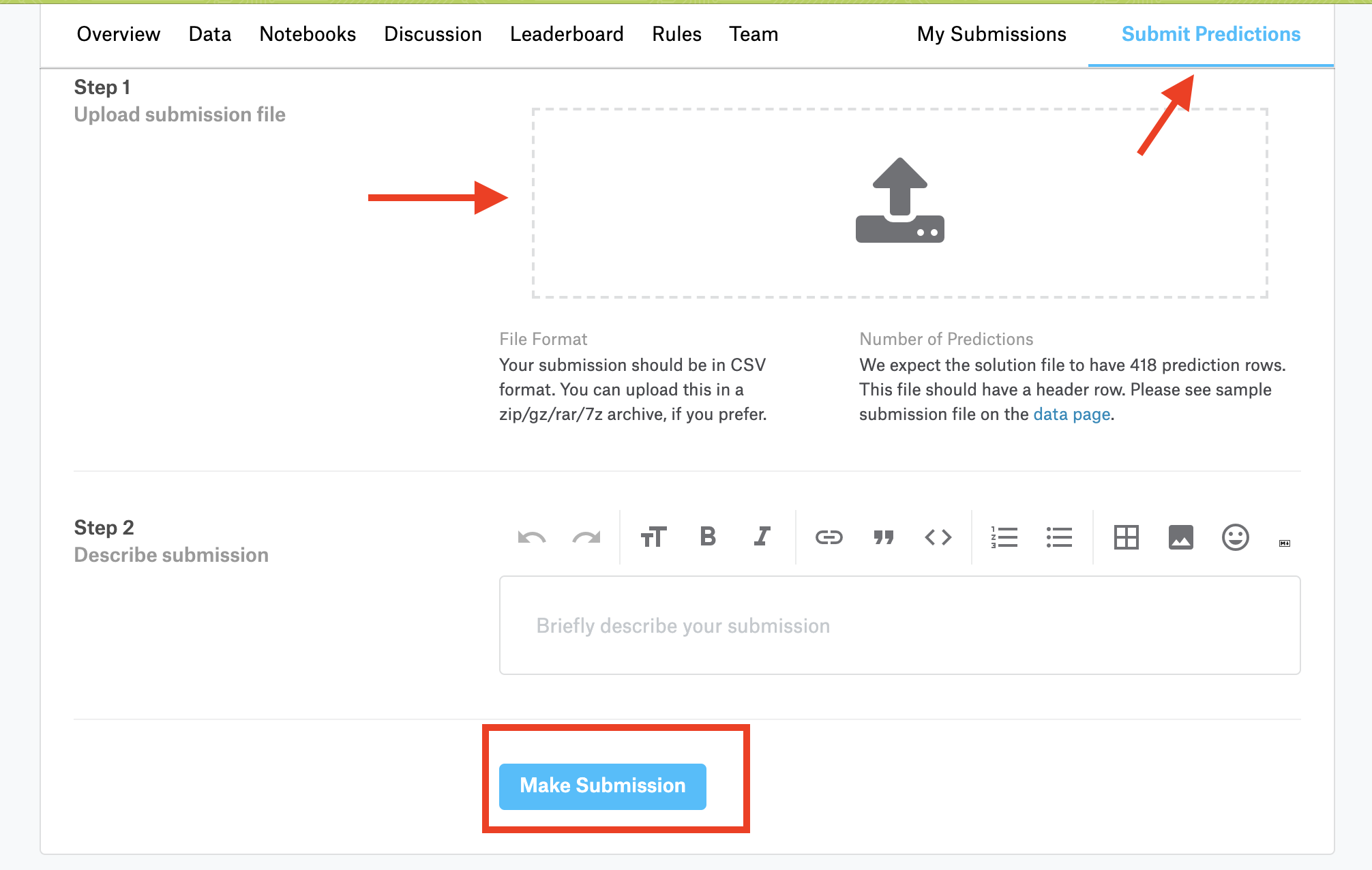
ফাইল আপলোড হওয়ার পর ডেটা প্রসেস করে আমাদের রেজাল্ট দেখাবে। দেখাবে স্কোর এবং লেডারবোর্ডে পজিশন।
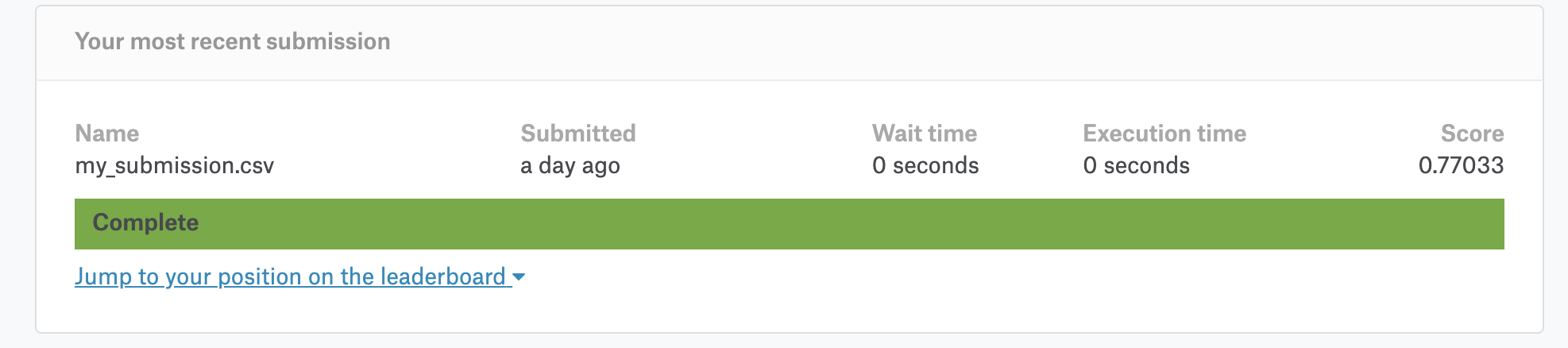
ঠিক মত আপলোড হলে এবং লেডারবোর্ডে আপনাকে দেখতে ফেলে কনগ্রেচুলেশন্স! আপনি সঠিক ভাবে ক্যাগেল কম্পিটিশনে জয়েন করতে পেরেছেন এবং প্রথম সাবমিশন করতে পেরেছেন। এটা অনেক বড় একটা স্টেপ! এখন বাকি স্টেপ গুলো অনেক সহজ হয়ে যাবে।
প্রিডিকশন ইম্প্রুভমেন্ট
এখন লেডারবোর্ডে আপনাকে হয়তো দেখবেন অনেক নিচের দিকে। ভাবতে পারেন কিভাবে নিজেকে উপরের দিকে দেখাতে পারি! তার জন্য আমাদের প্রিডিকশনটাকে ইম্প্রুভ করতে হবে। তার জন্য নতুন অনেক কিছুই শিখতে হবে। এছাড়া অন্যরা কিভাবে তাদের মডেল তৈরি করেছে, তা দেখেও আইডিয়া নিতে পারি। কম্পিটিশনের Notebooks নামে একটা ট্যাব দেখতে পাবেন। ঐখানে অনেকেই তাদের মডেল, তাড়া কিভাবে কাজ করেছে এসব শেয়ার করেছে। এগুলো দেখে দেখে আইডিয়া নিতে পারেন। আর পাশা পাশি নতুন নতুন টপিক্স গুলো শিখে নিতে পারেন।
মডেল ভ্যালিডেশন
প্রিডিকশন ইম্প্রুভ করার জন্য আমরা প্রথমে যা করতে পারি, তা হচ্ছে আমাদের মডেলটিকে ইভ্যালুয়েট করতে পারি। আমরা যে মডেল নিয়ে কাজ করব, তার একুরেসি নির্ণয় করাই হচ্ছে মডেল ভ্যালিডেশন। মডেল ইম্প্রুভ করতে আমরা মডেল ভ্যালিডেশন ব্যবহার করতে পারি। যেমন হয়তো আমরা কোন ফিচার যুক্ত করেছি বা কোন ফিচার রিমুভ করেছি, তারপর দেখলাম মডেল কেমন রেজাল্ট দেয়, এরপর যা ভালো রেজাল্ট দেয়, আমরা তাই সিলেক্ট করব। আর এই প্রসেসে হেল্প করবে মডেল ভ্যালিডেশন। এছাড়া একাদিক মডেলের মধ্যে কোন মডেলটা ভালো, তাও খুঁজে বের করতে পারি মডেল ভ্যালিডেশনের সাহায্যে।
অনেক ভাবেই মডেল ভ্যালিডেশন করা যায়। আমরা এখানে ব্যবহার করব Mean Absolute Error।
প্রতিটা মডেলই কিছু ভুল করে। ভুল হচ্ছে error=actual−predicted। মানে কেউ যদি মারা যায়, কিন্তু আমাদের মডেল যদি প্রিডিক্ট করে যে সে মারা যায় নাই, তাই হচ্ছে ভুল। এভাবে প্রতিটা রো এর ভুল গুলো যোগ করে এভারেজ বের করাই হচ্ছে Mean Absolute Error এর কাজ। এটি আমাদের একটা ধারনা দিবে আমরা মডেল কতটুকু কারেক্ট। আমরা এভাবে MAE বের করতে পারিঃ
predicted_data = model.predict(X) print(mean_absolute_error(y, predicted_data))
তার জন্য আমাদের mean_absolute_error প্যাকেজ ইম্পোর্ট করে নিতে হবে।
from sklearn.metrics import mean_absolute_error
Mean Absolute Error বের করার পর আমরা আমাদের মডেল ইম্প্রুভ করার চেষ্টা করব। যেমন নতুন অন্য আরেকটা মডেল সিলেক্ট করা অথবা ফিচার সিলেকশন ইত্যাদিতে। এরপর আবার Mean Absolute Error বের করব। যদি ভুলের রেট আগের থেকে কমে, তাহলে আমরা বুঝতে পারব আমাদের মডেল ইম্প্রুভ করেছে।
একটা সমস্যা রয়ে গিয়েছে। মডেল ট্রেইন করেছি যে ডেটা দিয়ে, সেই ডেটা দিয়ে যদি মডেল ভ্যালিডেট করার জন্য ব্যবহার করি, তাহলে আমারা ভুল প্রিডিকশন পেতে পারি। যে ডেটা দিয়ে ট্রেইন করেছি, একই ডেটা যদি প্রিডিকশনে ব্যবহার করি, তাহলে মডেল একুরেট রেজাল্ট দিবে কিন্তু টেস্ট করতে গেলে দেখা যাবে অতটা একুরেটলি আমাদের মডেল কাজ করছে না। এ জন্য আমরা একটা কাজ করতে পারি, তা হচ্ছে ট্রেইন ডেটাকে দুই ভাগ্যে ভাগ করতে পারি। একটা ট্রেইন করার জন্য, একটা ভ্যালুয়েশনের জন্য।
তা করতে পারি এভাবেঃ
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
এই স্প্লিট করা ডেটার কিছু ডেটা দিয়ে আমরা মডেল ট্রেইন করাবো। কিছু ডেটা মডেল ভ্যালিডেশনের জন্য ব্যবহার করব।
model.fit(train_X, train_y) val_predictions = model.predict(val_X) print(mean_absolute_error(val_y, val_predictions)
মডেল ভ্যালিডেশনের মাধ্যমে আমরা একটা ক্লাসিফায়ারের একুরেসি মাপতে পারি।
যেমন আমরা ডিসিশন ট্রি সম্পর্কে জেনেছি। এখন যদি জানতে চাই ডিসিশন ট্রি ভালো হবে নাকি র্যান্ডম ফরেস্ট ভালো হবে তা আমরা মডেল ভ্যালিডেশনের সাহায্যে বের করতে পারি।
যেমন মডেল হিসেবে যদি আমরা ডিসিশন ট্রি ব্যবহার করি, তাহলে MAE ভ্যালু পাবো 0.275228। যা র্যান্ডম ফরেস্ট মডেলের MAE ভ্যালু থেকে বেশি। তাই আমাদের র্যান্ডম ফরেস্ট ক্লাসিফায়ার ব্যবহার করাই ভালো হবে।
tree_model = DecisionTreeRegressor(random_state=1)
tree_model.fit(train_X, train_y)
tree_val_predictions = tree_model.predict(val_X)
print('MAE of Decision Tree: %f' % (mean_absolute_error(val_y, tree_val_predictions)))
সম্পূর্ণ প্রজেক্ট: গিটহাব লিঙ্ক।
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
# load data
train_data = pd.read_csv("data/train.csv")
test_data = pd.read_csv("data/test.csv")
# feature selection
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
y = train_data['Survived']
# split data to train set and validation set
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# Random forest prediction
forest_model = RandomForestClassifier(n_estimators=100)
forest_model.fit(train_X, train_y)
forest_val_predictions = forest_model.predict(val_X)
print('MAE of Random Forests: %f' % (mean_absolute_error(val_y, forest_val_predictions)))
# Decision Tree prediction
tree_model = DecisionTreeRegressor(random_state=1)
tree_model.fit(train_X, train_y)
tree_val_predictions = tree_model.predict(val_X)
print('MAE of Decision Tree: %f' % (mean_absolute_error(val_y, tree_val_predictions)))
# testing
X_test = pd.get_dummies(test_data[features])
predictions = forest_model.predict(X_test)
# generate CSV
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': forest_val_predictions})
output.to_csv('my_submission.csv', index=False)
print('csv generated.')
অসংখ্য ধন্যবাদ ভাইয়া। মেশিন লার্নিং রিলেটেড আরো পোস্ট চাই।
array length 223 does not match index length 418!!!!!!!!!!!!
Wow, I’m going to start ML from here.
Thanks a Lot Brother.
@NASIR UDDIN AHMED, একটু ভুল ছিল কোডে। CSV তৈরি করার সময় ভ্যালিডেশন সেটের ডেটা থেকে তৈরি করা হচ্ছিল। এখন তা ঠিক করা হয়েছে।