
ডিপ লার্নিং নিয়ে এর আগের লেখাটিঃ ডিপ লার্নিং এ সূচনা
মডেল
সমস্যা সমাধান করার জন্য আমরা যে সিস্টেম দাঁড় করাই, তা হচ্ছে মডেল। মডেলের কাজ হচ্ছে ইনপুট এবং আউটপুটের মধ্যে একটা কানেকশন তৈরি করা। আর এই কানেকশনটা প্রথমে ভুল করে। পরে শিখতে শিখতে ভুলের পরিমাণ কমতে থাকে।
অ্যাকুরেসি
ট্রেইনিং এর সময় আমরা মডেলকে ইনপুট বা ফিচার এবং আউপুট বা লেভেল দুইটাই দিয়ে থাকি। ট্রেনিং করা শেষে টেস্ট করার জন্য টেস্টিং ডেটা দিয়ে টেস্ট করি। যেখানে শুধু ফিচার থাকে, লেভেল থাকে না। এরপর মডেল দিয়ে আউটপুট প্রিডিক্ট করি। মডেল কতটুকু একুরেট, তা পাওয়ার জন্য ট্রেনিং এর সময় এই প্রিডিকশনের সাথে টেস্টিং ডেটাসেটের লেভেল কম্পেয়ার করে। যাকে বলা হয় একুরেসি।
ভ্যালিডেশন ডেটাসেট
মডেল ট্রেইন করার সময় আমাদের লক্ষ্য থাকে ট্রেইনিং এর সময় লস মিনিমাইজ করা। তো আমাদের মডেল কেমন পারফর্ম করে, তা বুঝার জন্য টেস্ট করতে হয়। আর এই টেস্ট করা হয় নতুন ডেটাসেট দিয়ে। যেন বুঝা যায় মডেল নতুন ডেটার উপর কেমন কাজ করে। এই নতুন ডেটাসেটকে বলি ভ্যালিডেশন ডেটাসেট। যদি আমরা সেইম ডেটাসেট দিয়ে টেস্ট করি, তাহলে তো মডেল মুখস্ত বলে দিবে উত্তর। যেমন আমরা মানুষেরা করি!
সাধারণ ডেটাসেট একটাই হয়। অনেক গুলো ডেটাসেটে আবার ট্রেইনিং ডেটা এবং টেস্টিং ডেটা ভাগ করা থাকে। যেসব ডেটাসেটে ট্রেইনিং এবং টেস্টিং ডেটা ভাগ করা থাকে না, সেগুলোকে আমরা ভাগ করে নেই। যাকে বলে ট্রেইনিং টেস্টিং স্প্লিট।
লার্নিং কার্ভস
ট্রেইন করার সময় আমরা ট্রেইনিং ডেটার লসের পাশা পাশী ভ্যালিডেশন ডেটার লসও দেখি। এই দুইটা লস এক সাথে প্লট করলে আমরা পাবো লার্নিং কার্ভস। আর মেশিন লার্নিং এ মডেল টিউনিং করার জন্য মানে মডেল কেমন কাজ করছে, তা বুঝার জন্য এই লার্নিং কার্ভটা বুঝা গুরুত্বপূর্ণ।
প্রথম প্রথম মনে হবে একটা গ্রাফ, এটা থেকে কিই বা বুঝার আছে। কিন্তু কয়েকটা প্রজেক্ট করার পর তাদের লার্নিং কার্ভস দেখেই আমরা বুঝে যাবো আমাদের মডেলের কি সমস্যা, কি ইম্প্রুভ করতে হবে ইত্যাদি।
আন্ডারফিটিং
মডেল যদি ঠিক মত শিখতে না পারে, তাহলে আন্ডারফিটিং হয়। সমস্যা সমাধান করার জন্য যদি আমরা খুবি সিম্পল একটা মডেল তৈরি করি তাহলে তা ঠিক মত ফিচার এবং লেভেলের মধ্যে কানেকশন তৈরি করতে পারবে না। আর এর ফলে খুব খারাপ প্রিডিকশন করবে।
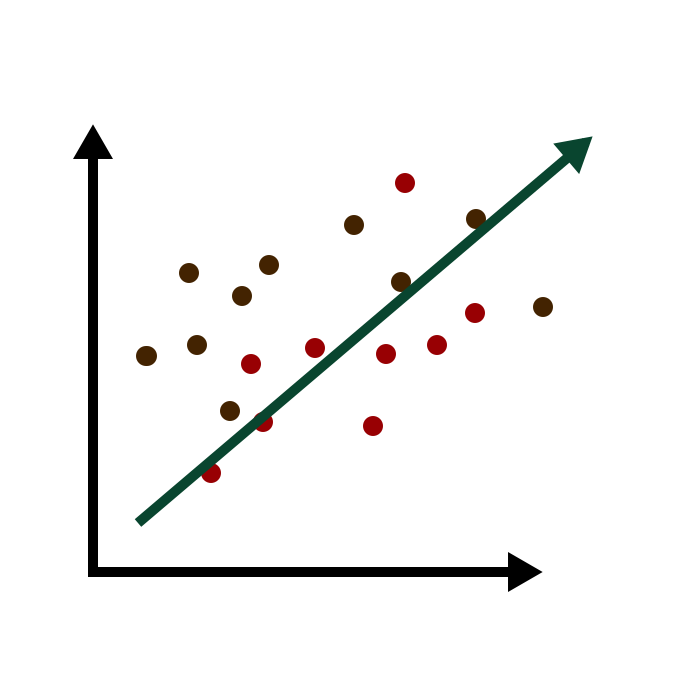
আন্ডারফিটিং এ মডেল পর্যাপ্ত পরিমাণ ভ্যারিয়েবল পায় না সমস্যা সমাধান করার জন্য। যেমন সমস্যাটা লিনিয়ার রিগ্রেশন দিয়ে সমাধান করা যাবে না, কিন্তু আমরা লিনিয়ার রিগ্রেশন মডেল দিয়ে সমাধান করতে চেয়েছি। এতে মডেল ডেটা থেকে ঠিক মত শিখতে পারে নি, একুরেসিও কম দিবে।
আন্ডারফিটিং সমস্যা সমাধান
কয়েক ভাবে আন্ডারফিটিং সমস্যা সমাধান করা যায়। যেমনঃ
- ডেটার পরিমাণ বাড়ানো
- ফিচারের পরিমাণ কমানো
- মডেলের ক্যাপাসিটি বাড়ানো
- ডেটা থেকে নয়েজ কমানো
- ট্রেনিং ডিউরেশন বাড়ানো ইত্যাদি।
ওভারফিটিং
ট্রেনিং এর সময় মডেল যদি ফিচার এবং লেভেলর মধ্যে জেনারেল একটা কানেকশন তৈরির পরিবর্তে হুবহু ম্যাপ করে ফেলে, তাহলে অভারফিটিং হয়। উত্তর মুখস্ত করে ফেলার মত অবস্থা।
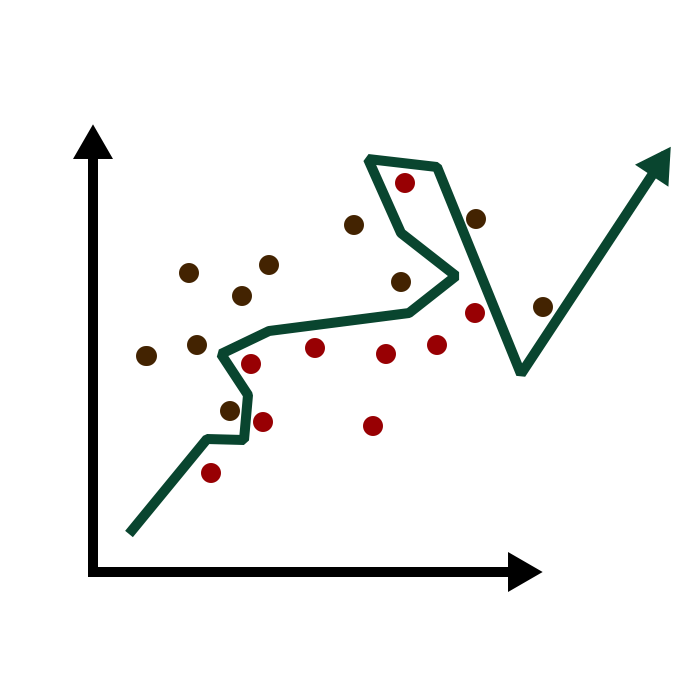
সাধারণত মডেল যদি সমস্যা থেকে বেশি কমপ্লেক্স হয়, তাহলে অভারফিটিং হতে পারে। ওভারফিটিং মডেল ট্রেনিং ডেটার উপর ভালো একুরেসি দিলেও নতুন ডেটার ক্ষেত্রে একুরেসি খুব একটা ভালো দিতে পারে না।
ওভারফিটিং কেমন, তা বুঝার জন্য একটা মিম শেয়ার দিচ্ছিঃ

ওভারফিটিং সমস্যা সমাধান
- ট্রেনিং ডেটার পরিমাণ বাড়ানো
- মডেল কমপ্লিক্সিটি কমানো
- আর্লি স্টপিং
- ড্রপআউট
- ডেটা অগমেন্টেশন
- রেগুলারাইজেশন ইত্যাদি।
মডেল ক্যাপাসিটি
মডেল কতটুকু কমপ্লেক্স প্যাটার্ন শিখতে পারে, তাই হচ্ছে মডেলের ক্যাপাসিটি। নিউরাল নেটওয়ার্কের ক্ষেত্রে এই ক্যাপাসিটি নিউরনের সংখ্যা এবং তারা কিভাবে কানেক্টেড, তার উপর নির্ভর করে। মডেল যদি আন্ডারফিটিং হয়, তাহলে উচিত এর ক্যাপাসিটি বৃদ্ধি করা। দুই ভাবে নিউরালনেটের ক্যাপাসিটি বাড়ানো যায়। নতুন লেয়ার যুক্ত করে অথবা মডেলের লেয়ারে নিউরনের সংখ্যা বাড়িয়ে।
প্রথমে একটা সিম্পল মডেলটির দেখিঃ
model = keras.Sequential([
layers.Dense(128, activation='relu'),
layers.Dense(16),
])
এবার আমরা এর ক্যাপাসিটি দুই ভাবে বাড়াতে পারি, প্রথমে বাড়িয়েছি নিউরনের সংখ্যা। এরপর বাড়িয়েছি লেয়ারের সংখ্যাঃ
wider = keras.Sequential([
layers.Dense(128, activation='relu'),
layers.Dense(1),
])
deeper = keras.Sequential([
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1),
])
আর্লি স্টপিং
ভ্যালিডেশন লস বৃদ্ধি পায় যখন মডেল জেনারেল প্যাটার্ন খুঁজে বের করার পরিবর্তে ট্রেইনিং ডেটা মুখস্ত করা শুরু করে। আর এই সমস্যা সমাধান করার জন্য যখনই দেখব ভ্যালিডেশন লস আর কমতেছে না, উল্টো বাড়া শুরু করছে তখনই ট্রেনিং বন্ধ করে দিব।
আর্লি স্টপিং এর জন্য কেরাসে কলব্যাক তৈরি করা আছে। নিচের মত করে আমরা এই কলব্যাকটির প্যারামিটার সেট করতে পারি।
early_stopping = EarlyStopping(monitor='loss', patience=10)
এখানে monitor=‘loss’ দিয়ে বলে দিচ্ছি আর্লি স্টপিং এর জন্য কোন ডেটা মনিটর করবে। এখানে ট্রেইনিং ডেটার লস মনিটর করতে বলেছি, আমরা চাইলে ভ্যালিডেশন লসও ব্যবহার করতে পারি। patience=10 দিয়ে বলে দিচ্ছি ইম্প্রুভ না হওয়ার কতটা ইপক পর্যন্ত অপেক্ষা করবে। ১০টা ইপকের পরও যদি ইম্প্রুভ না হয়, তাহলে ট্রেনিং বন্ধ করে দিবে। আর্লি স্টপিং এ নিচের মত আর্গুমেন্ট গুলো পাস করা যায়। আর কোনটার কাজ কি, তা নিচের টেবিলে বিস্তারিত লিখেছি।
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0, patience=0, verbose=0,
mode='auto', baseline=None, restore_best_weights=False
)
আর্গুমেন্ট |
কাজ |
|---|---|
monitor |
কি মনিটর করবে তা, হতে পারে ট্রেনিং লস, হতে পারে ভ্যালিডেশন লস। |
min_ |
মিনিমাম ভ্যালু যে ভ্যালুকে ইম্প্রুভমেন্ট হিসেবে কাউন্ট করবে। |
patience |
ইম্প্রুভমেন্ট না দেখার পরও যে কয়টা ইপক ট্রেনিং চালিয়ে যাবে। |
verbose |
verbosity mode. |
mode |
{"auto", এর একটা। . min এর ক্ষেত্রে, মনিটরের ভ্যালু কমা বন্ধ করলে ট্রেনিং বন্ধ করবে। ;"max" এর ক্ষেত্রে মনিটরের ভ্যালু বাড়া বন্ধ করলে ট্রেনিং বন্ধ করবে; "auto" এর ক্ষেত্রে মডেল নিজে বুঝে নিবে কোনটা করবে। |
baseline |
যে ভ্যালুটা মনিটর করবে, তার একটা Baseline value। এই বেসলাইন ভ্যালু থেকে ইম্প্রুভ না করলে ট্রেনিং বন্ধ করে দিবে। |
restore_ |
মডেলের ওয়েট রিস্টোর করবে কি করবে না, তা সেট করা। False সেট করলে ট্রেইনিং এর লাস্ট স্টেপে যে ওয়েট পেয়েছে, তা ব্যবহা করবে। আর True হলে পারফরমেন্স অনুযায়ী একটা ইপক রিস্টোর করবে। যদি তা বেসলাইন থেকে আর কোন ইম্প্রুভ না হয়, তাহলে patience ইপক সেট থেকে বেস্ট ওয়েট রিস্টোর করবে। |
ড্রপআউট
ওভারফিটিং সমস্যা সমাধান করার জন্য আরেকটা পদ্ধতি হচ্ছে মডেলে ড্রপআউট লেয়ার যুক্ত করা। মডেল ট্রেনিং এর সময় একটা নির্দিষ্ট সময় পর ফিচার এবং লেভেলের মধ্যে একটা জেনারেল কানেকশন বের করার পরিবর্তে মুখস্ত একটা প্যাটার্ন তৈরি করে ফেলে। আর এই মুখস্ত প্যাটার্নটি ভেঙ্গে দেওয়ার জন্য লেয়ারের মধ্য থেকে একটা অংশ যদি ড্রপ করে দিতে পারি, তাহলে আর মুখস্ত করতে পারে না। যে কোন লেয়ারের আগে আমরা ড্রপআউট লেয়ার যুক্ত করতে পারি।
layers.Dropout(0.2),
কত পার্সেন্ট নিউরন ড্রপআউট করবে, তা বলতে দিতে পারি আমরা।
ডেটা অগমেন্টেশন
ট্রেনিং ডেটার পরিমাণ বাড়ালে ওভারফিটিং এবং আন্ডারফিটিং দুইটা সমস্যাই সমাধান হয়ে যায়। আর্টিফিশিয়ালি আমরা চাইলে ডেটার পরিমাণ বাড়িয়ে নিতে পারি। আর্টিফিশিয়াল ভাবে ডেটার পরিমাণ বাড়িয়ে নেওয়া হচ্ছে ডেটা অগমেন্টেশন। ইমেজের ক্ষেত্রে চিন্তা করি। একটা ইমেজকে কয়েক ভাবে ট্রান্সফরম করা যায়, যেমন কালার ইমেজকে গ্রে স্কেলে নেওয়া, ইমেজ ক্রপ করা, জুম করা, ইমেজকে হরিজন্টালি বা ভার্টিক্যালি ফ্লিপ করা ইত্যাদি। একটা ইমেজকে এভাবে ট্রান্সফরম করে অনেক গুলো নতুন ইমেজ পাওয়া যায়। ডেটার পরিমাণ বেড়ে যায়।
ডেটা অগমেন্টেশন নিয়ে ইনশাহ আল্লাহ সামনে বিস্তারিত লেখা লিখব।
ব্যাচ নরমালাইজেশন
ট্রেইনিং এর জন্য ডেটাকে প্রস্তুত করাকে বলে নরমালাইজেশন। এর কাজ মূলত ডেটাকে সেইম স্কেলে কনভার্ট করা। মেশিন লার্নিং মডেলের একটা লেয়ারের এক্টিভেশন ফাংশন থেকে থেকে প্রাপ্ত আউটপুটকে নরমালাইজ করে পরের লেয়ারের জন্য প্রস্তুত করা হচ্ছে ব্যাচ নরমালাইজেশন। ব্যাচ নরমালাইজেশন লেয়ার মডেলের যে কোন যায়গায় ব্যবহার করা যায়। ব্যাচ নরমালাইজের জন্য শুধু নিচের লেয়ারটি যুক্ত করে দিলেই হবেঃ
layers.BatchNormalization()
এই লেখায় যে টপিক্স গুলো শিখেছি, সেগুলো এবার আমরা এপ্লাই করতে পারি। এখানের কোড ব্লক গুলো আলাদা আলাদা ব্লকে লিখে রান করলে বুঝতে সুবিধে হবে। দেখতে সুবিধার জন্য আমি সব গুলো এক সাথে দিচ্ছি। গুগল কোল্যাব লিঙ্ক। ডেটা সেট ডাউনলোড করে নেওয়া যাবে ক্যাগেল Heart Attack Analysis & Prediction Dataset থেকে।
import numpy as np
import pandas as pd
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers
from tensorflow.keras import layers, callbacks
from tensorflow.keras.callbacks import EarlyStopping
# if it gives error, you have to upload dataset
# Download the dataset from here: https://www.kaggle.com/rashikrahmanpritom/heart-attack-analysis-prediction-dataset
dataset = pd.read_csv('heart.csv')
dataset.head()
dataset.info()
# labels or taret value
y = dataset['output']
# removing output data from training data
X = dataset.drop(columns=['output'])
# train test split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.2)
# Early stopping callback
# This callback will stop the training when there is no improvement for 10 consecutive epochs.
early_stopping = EarlyStopping(monitor='loss', patience=10)
# creating model
model = keras.Sequential([
layers.InputLayer(input_shape=(13)),
layers.Dense(500, activation='relu'),
layers.BatchNormalization(),
layers.Dense(500, activation='relu'),
layers.Dropout(0.2),
layers.Dense(1, activation='linear')
])
# model compile
model.compile(loss='mae', metrics=['accuracy'],
optimizer='adam')
# model training
history = model.fit(X_train, y_train, epochs=100,
validation_data=(X_test, y_test),
callbacks=[early_stopping]
)
# plotting accuracy
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['accuracy', 'val_accuracy']].plot()
আর্টিফিশিয়াল ইন্টিলিজেন্স এবং মেশিন লার্নিং নিয়ে অন্যান্য লেখা গুলো।