যে কোন ডেটা সম্পর্কে কুইক আইডিয়া পাওয়ার জন্য পান্ডার descrive() ফাংশন খুব ভালো কাজে দেয়। কিন্তু আমরা যদি ডেটা সম্পর্কে আরো বেশি জানতে চাই, তাহলে কি করব? নিজেরা কোড করব? হ্যাঁ। তা একটা ভালো আইডিয়া। কিন্তু অনেক গুলো সময় নষ্ট করবে। সময় নষ্ট করতে না চাইলে পান্ডা প্রোফাইলিং ব্যবহার করতে পারি। এটা খুবি দারুণ একটা মডিউল। এটা দিয়ে ডেটার একটা পূর্নাঙ্গ প্রোফাইল পাওয়া যাবে। যা HTML ফাইল তৈরি করে দিবে। এবং আমরা খুব সুন্দর করে সব কিছু দেখতে পাবো।
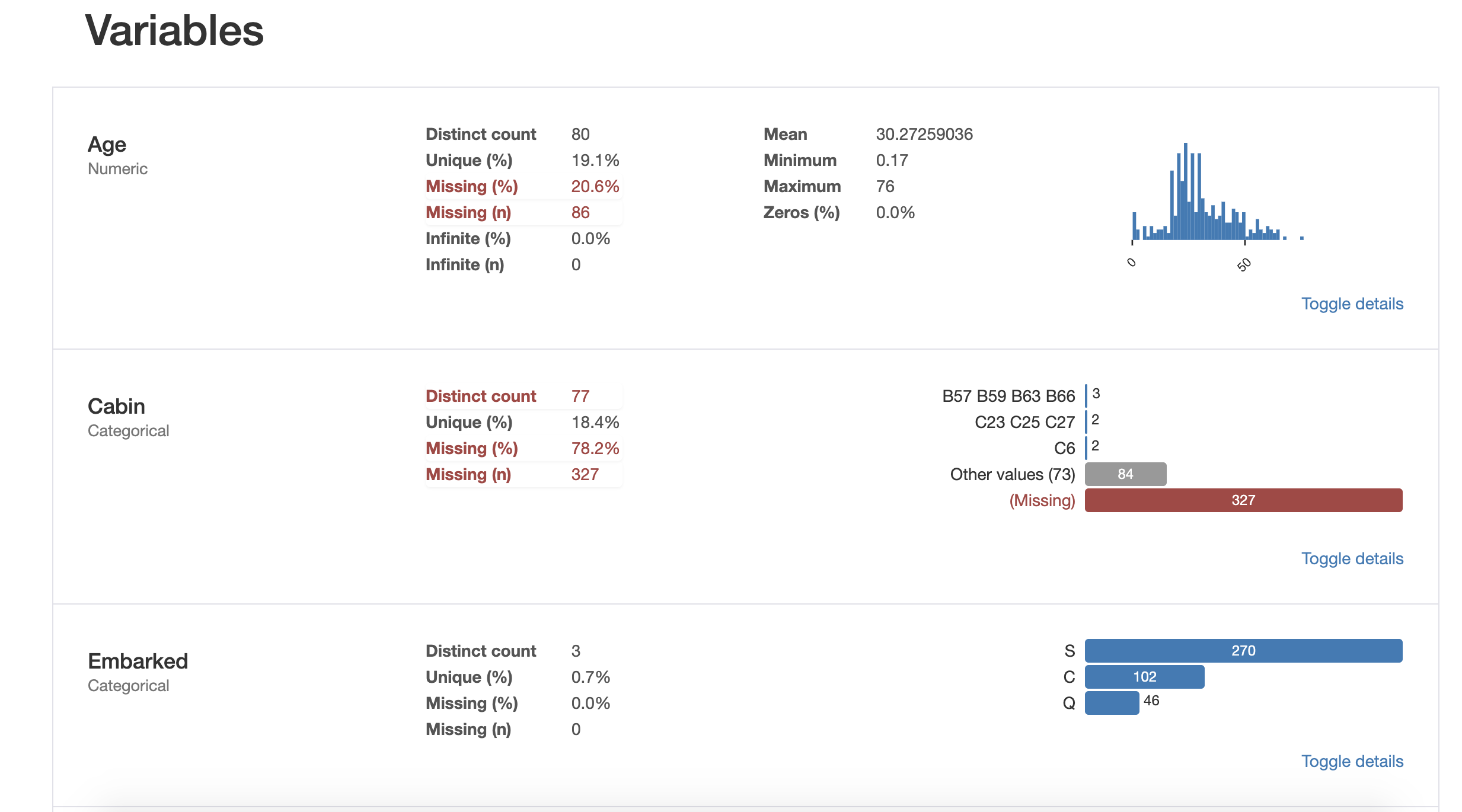
যা দিয়ে ডেটাসেটের প্রতিটি কলামের নিচের ইনফরমমেশন গুলো জানা যাবেঃ
- Essentials: type, unique values, missing values
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
- Histogram
- Correlations highlighting of highly correlated variables, Spearman, Pearson and Kendall matrices
- Missing values matrix, count, heatmap and dendrogram of missing values
ইন্সটল করা খুবি সহজ। pip দিয়ে ইন্সটল করতেঃ
<br /> pip install pandas-profiling<br /> [python]<br /> অথবা conda দিয়ে ইন্সটল করতেঃ<br /> [python]<br /> conda install -c conda-forge pandas-profiling<br />
ব্যবহার করা আরো সহজ। দুই লাইনের কোড দিয়ে যে কোন ডেটার উপর বিশাল একটা রিপোর্ট তৈরি করে ফেলা যাবে। পরে তা ব্রাউজারে দেখা যাবে। যে কোন একটা ডেটাসেট ডাউনলোড করে নিব প্রথমে। যেমন আমি ডাউনলোড করে নিলাম টাইটানিক ডেটা সেট। এরপর নিচের মত কোড লিখে জেনারেট করে নিলাম একটা পূর্নাঙ্গ রিপোর্ট।
গিটহাব থেকে ডাউনলোড করেও এই প্রজেক্টটা রান করা যাবে।
<br /> import pandas as pd<br /> import pandas_profiling</p> <p># load data<br /> train_data = pd.read_csv("data/train.csv")</p> <p>profile = train_data.profile_report(title='Pandas Profiling Report')<br /> profile.to_file(output_file="output.html")</p> <p>
মেশিং লার্নিং এবং ডেটা সাইন্স নিয়ে এই ব্লগে অনেক গুলো লেখা রয়েছে। সব গুলো পাওয়া যাবে নিচের লিঙ্কেঃ
Many many thanks.