ডাটা এনালাইসিসের জন্য একটা জনপ্রিয় লাইব্রেরি হচ্ছে পান্ডা / Pandas।
- এই চমৎকার লাইব্রেরি দিয়ে রিমোট ফাইল থেকে ডেটা লোড, লোকাল ফাইল থেকে বা ডাটাবেজ থেকে ডেটা লোড করা যায়।
- খুব সহজে ডেটার সামারি, স্ট্যাটিসটিক্স বা ডেটা সম্পর্কে আইডিয়া নেওয়া যায়।
- ডেটা ক্লিন করা, ডেটা ম্যানিপুলেট, ডেটা কম্বাইন সহ দরকারি সব কাজই পান্ডার সাহায্যে করা যায়।
- বড় ডেটা সেট নিয়েও খুব সহজে কাজ করা যায়।
- এছাড়া ডেটা নিয়ে সাধারণ যে সব প্রশ্ন আসে আমাদের মাথায়, সে সব প্রশ্নের উত্তরও আমরা পান্ডার সাহায্যে বের করতে পারি।
![]()
পান্ডা নিয়ে কাজ করার জন্য প্রথমে পান্ডা ইন্সটল করতে হবে। অনেক ভাবেই ইন্সটল করা যায়। খুব সহজে করতে চাইলে Anaconda ইন্সটল করে নিলেই হবে। Panda সহ ডেটা ইঞ্জিনিয়ারিং এর জন্য প্রয়োজনীয় সকল লাইব্রেরি ইন্সটল হবে। প্রোগ্রাম লেখার জন্য যে কোন কোড এডিটর ব্যবহার করলেই হবে। যদিও পাইথনের জন্য PyCharm অনেক দারুণ একটা IDE।
পান্ডা নিয়ে কাজ করার জন্য প্রজেক্টে পান্ডা ইম্পোর্ট করে নিতে হয়।
import pandas as pd
ডেটা তৈরি
পাণ্ডাতে দুইটা প্রধান অবজেক্ট রয়েছে, DataFrame এবং Series। এই দুইটা ব্যবহার করে কিভাবে ডেটা তৈরি করা যায়, তা দেখব। প্রথমে দেখি DataFrame দিয়ে কিভাবে ডেটা তৈরি করা যায়।
ডেটাফ্রেম
ডেটাফ্রেমে আলাদা আলাদা তালিকার অ্যারে থাকে। প্রতিটা তালিকার আলাদা আলাদা ভ্যালু থাকে। ডেটাফ্রেম হচ্ছে টেবিলের মত। তালিকার ভ্যালু গুলো টেবিলের রো, এবং কলাম রিপ্রেজেন্ট করে। যেমনঃ
pd.DataFrame({'first_name': ['Tom', 'Morgan'], 'last_name': ['Hanks', 'Freeman']})
যা নিচের মত ডেটা তৈরি করবে।
| first_name
|
last_name | |
| 0 | Tom | Hanks |
| 1 | Morgan | Freeman |
পুরো প্রজেক্টঃ
import pandas as pd
df = pd.DataFrame({'first_name': ['Tom', 'Morgan'],
'last_name': ['Hanks', 'Freeman']})
print(df)
যেখানে উপরের ডেটাফ্রেমে first_name তালিকার ভ্যালু গুলো হচ্ছে Tom, Morgan। last_name তালিকার ভ্যালু গুলো হচ্ছে Hanks, Freeman ইত্যাদি।
পাইথন পান্ডা এর ডেটাফ্রেমে আমরা যে কোন টাইপের ডেটা রাখতে পারি। যেমন ইন্টিজার, ক্যারেক্টার, লজিক্যাল ইত্যাদি।
উপড়ে যদি খেয়াল করি, আমরা দেখব 0,1 এভাবে প্রতিটা রো এর একটা লেভেল রয়েছে। এটা অটো জেনারেটেড। আমরা চাইলে নিজেদের ইচ্ছে মত লেভেল দিতে পারি। যাকে বলে ইনডেক্স। ইনডেক্স ব্যবহার করতে পারি এভাবেঃ
pd.DataFrame({'first_name': ['Tom', 'Morgan'],'last_name': ['Hanks', 'Freeman']}, index=['About Tom', 'About Morgan'])
|
|
first_name
|
last_name |
| About Tom | Tom | Hanks |
| About Morgan | Morgan | Freeman |
পুরো প্রজেক্টঃ
import pandas as pd
df = pd.DataFrame({'first_name': ['Tom', 'Morgan'],'last_name': ['Hanks', 'Freeman']},index=['About Tom', 'About Morgan'])
print(df)
উপড়ে আমরা স্ট্রিং নিয়ে কাজ করেছি। আমরা চাইলে যে কোন ডেটা ডেটাফ্রেমে রাখতে পারি।
সিরিজ
সিরিজ হচ্ছে ডেটা লিস্টের সিকোয়েন্স। সিরিজকে একটা লিস্ট বলা যায় বা ডেটাফ্রেম টেবিলের একটা কলামের মত।
যেমন
pd.Series([1, 2, 3, 4, 5])
সিরিজেও আমরা index ব্যবহার করতে পারি।
pd.Series([1, 2, 3, 4, 5], index=[‘one’, ‘two’, ‘three’])
সম্পূর্ণ প্রজেক্টঃ
import pandas as pd df = pd.Series([1, 2, 3], index=['one', 'two', 'three']) print(df)
যা নিচের মত আউটপুট দিবেঃ
one 1
two 2
three 3
রিয়েল প্রজেক্টে আমাদের ডেটাফ্রেম তৈরি করতে হবে না। ডেটা ইঞ্জিনিয়ারিং এর জন্য আমাদের ডেটা থাকবে। তা আমরা শুধু রিড করে নিব। ডেটা অনেক ভাবেই থাকতে পারে। বেশির ভাগ সময় CSV আকারে থাকে। আমরা এখানে দেখব কিভাবে CSV থেকে পড়া যায়।
আমরা এখানে আইরিশ ডেটাসেট ইম্পোর্ট করব। একটু খুঁজলে অনেক গুলো ফ্রি এবং ওপেনসোর্স ডেটাসেট পাওয়া যাবে। যেমন ক্যাগেল এর ডেটাসেট, awesome-public-datasets ইত্যাদি।
CSV রিড করতে চাইলেঃ
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
এখন আমরা চাচ্ছি ডেটাসেট এ কত গুলো রেকর্ড রয়েছে, কত গুলো কলামে ডেটা ভাগ করা রয়েছে, তার জন্য আমরা ব্যবহার করতে পারি shape এট্রিবিউট।
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.shape)
উপরের প্রোগ্রামটা রান করলে আমরা দেখব (150, 5)। এর মানে এই ডেটাসেটে টোটাল ১৫০টা রেকর্ড রয়েছে। প্রতিটি রেকর্ড ৫টি কলামে বিভক্ত রয়েছে।
ডেটা সম্পর্কে একটা ধারণা পাওয়ার জন্য আমরা head কমান্ড ব্যবহার করতে পারি। যা আমাদের প্রথম ৫টা রো রিটার্ণ করবে।
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.head())
উপরের প্রোগ্রাম রান করলে আমরা দেখব প্রথম ৫টি রো দেখাচ্ছে। এখান থেকে আমরা ডেটাসেট সম্পর্কে একটা আইডিয়া পাবো। আমরা যদি চাই একটা মিনিংফুল আইডিয়া নিতে, তাহলে ব্যবহার করতে পারি describe() এট্রিবিউট।
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.describe())
যা আমাদের অনেক গুলো মিনিংফুল তথ্য দিবে যেমন count, mean, std, min ইত্যাদি। নিচের মত করেঃ
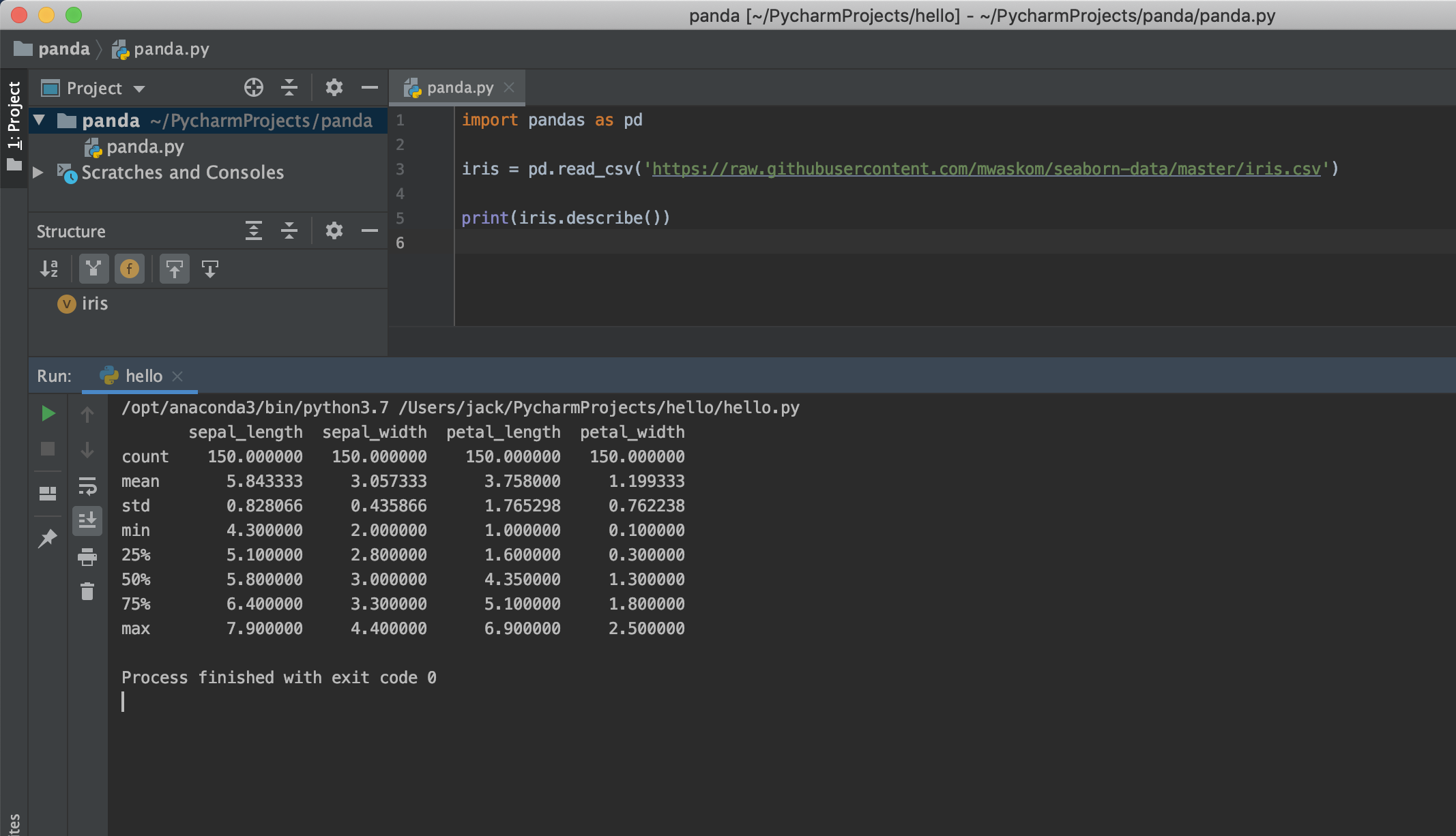
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
ডেটা সাইন্স নিয়ে এই ব্লগে আরো কিছু লেখা রয়েছে। সব গুলো পাওয়া যাবে ডেটা সাইন্স পেইজে।