টেনসরফ্লো ব্যবহার করে আমরা হাতে লেখা সংখ্যা ক্লাসিফাই করার জন্য একটা নিউরাল নেট ট্রেইন করব। ডীপ লার্নিং এর মাধ্যমে ইমেজ রিকগনিশনের হ্যালো ওয়ার্ল্ড প্রোগ্রাম বলা যেতে পারে এই প্রোগ্রামটিকে। আর এর জন্য আমরা MNIST ডেটাসেট ব্যবহার করব।
MNIST Handwritten Digit ডেটাসেটে মোট ৭০ হাজার 28*28 পিক্সেলের গ্রেস্কেল ইমেজ রয়েছে, যেগুলোর প্রতিটাতে 0-9 পর্যন্ত যে কোন একটা সংখ্যা রয়েছে। এর মধ্যে ৬০ হাজার ইমেজ হচ্ছে ট্রেইন করার জন্য, বাকি ১০ হাজার টেস্ট করার জন্য। সম্পূর্ণ প্রজেক্টটি গুগল কো-ল্যাব থেকে দেখা এবং রান করা যাবে।

ডেটা ইম্পোর্ট
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np # import MNIST Handwritten-Digits dataset from the Keras library mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() # checking is everything imported correctly plt.imshow(x_train[0], cmap="gray") plt.show()
কতগুলো ডেটা রয়েছে, তা দেখতে চাইলে এভাবে দেখতে পারিঃ
print(x_train.shape) print(x_test.shape)
ডেটা প্রি-প্রসেস
স্বাধারনত যে কোন ডেটা নিয়ে কাজ করার ক্ষেত্রে ডেটাকে প্রি-প্রসেস করে নিতে হয়। ডেটার ভুল গুলো ঠিক করা, মিসিং ডেটা বাদ দেওয়া সহ অন্যান্য কাজ। আমাদের জন্য এই ডেটাসেটটি প্রি-প্রসেস করে দেওয়া আছে।
আমরা শুধু ডেটা গুলোকে নরমালাইজ করে নিব। এখানে ইমেজের প্রতিটা পিক্সেল ভ্যালু দেওয়া আছে 0-255 এর মধ্যে। আমরা 0-1 এ নরমালাইজ করে নিব। এতে কম্পিউটেশন পাওয়ার কম লাগবে। দ্রুত মডেল ট্রেইন করা যাবে।
# Normalize the train dataset x_train = tf.keras.utils.normalize(x_train, axis=1) # Normalize the test dataset x_test = tf.keras.utils.normalize(x_test, axis=1)
ডেটা প্রসেস করার পর কেমন দেখাচ্ছে, তাও দেখতে পারিঃ
# checking processed data plt.imshow(x_train[0], cmap="gray") plt.show()
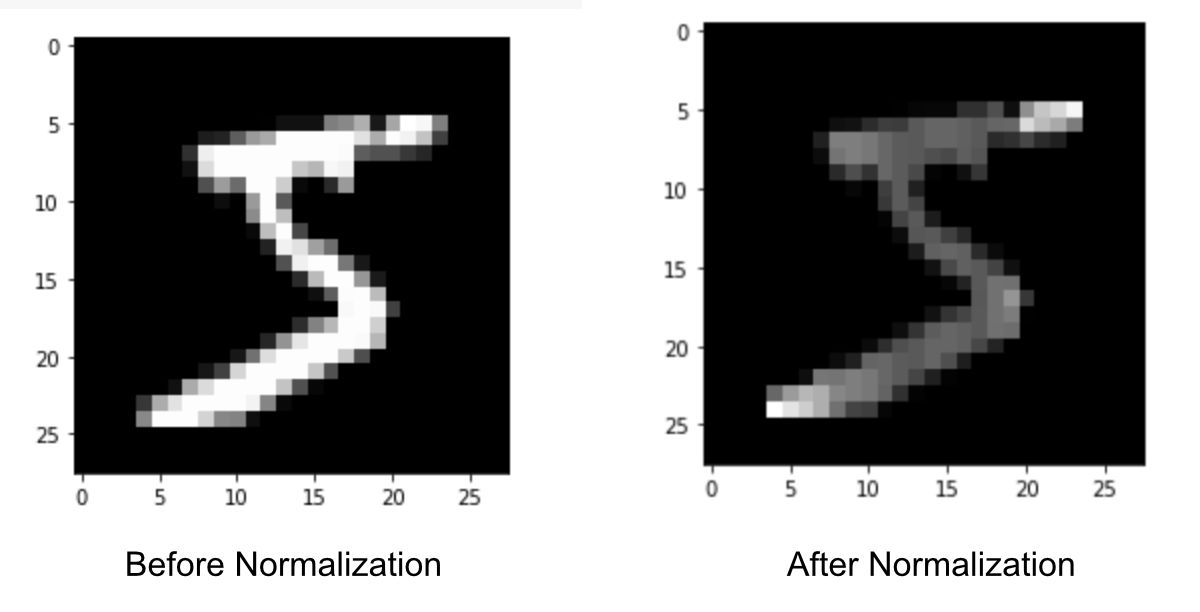
দেখতে পাবো যে ডেটার মূল ফিচারে কোন পরিবর্তন হয়নি।
মডেল তৈরি / মডেল ট্রেইন করা
এই স্টেপে আমরা আমাদের মডেল তৈরি করার জন্য প্রস্তুত। আর্টিফিশিয়াল নিউরাল নেটওয়ার্কের লেয়ার সবচেয়ে গুরুত্বপূর্ণ অংশ। কারণ এই লেয়ারই ডেটা থেকে ফিচার বের করে।
প্রথমে আমরা একটা মডেল অবজেক্ট তৈরি করে নিব। এরপর 28×28 dimensional ডেটাকে 1×784 ডাইমেনশন ডেটাতে পরিণত করব। একে বলে ডেটা ফ্ল্যাটেনিং। এটি হবে আমাদের ইনপুট লেয়ার।
হিডেন লেয়ারে 128 নিউরনের একটা লেয়ার নিব, যেখানে এক্টিভেশন ফাংশন হিসেবে RELU ব্যবহার করব। এবং ফাইনাল লেয়ার বা আউটপুট লেয়ার হিসেবে ১০ নিউরনের একটা লেয়ার নিব, যেখানে এক্টিভেশন ফাংশন হিসেবে ব্যবহার করব softmax এক্টিভেশন।
# build the model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
মডেল কম্পাইল
# Compile the model model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
মডেল কম্পাইল করার ক্ষেত্রে আমরা এডাম অপটিমাইজার ব্যবহার করেছি। লস ফাংশন হিসেবে ব্যবহার করেছি sparse categorical crossentropy ফাংশন।
মডেল ট্রেইন করা
সবচেয়ে সহজ পার্ট।
# train the model model.fit(x=x_train, y=y_train, epochs=5)
মডেলের কার্যকারিতা মূল্যায়ন / Evaluate Accuracy
আমাদের মডেলটি কেমন কাজ করছে টেস্ট ডেটার উপর, তা বের করতেঃ
# Evaluate the model performance
test_loss, test_acc = model.evaluate(x=x_test, y=y_test)
# Print out the model accuracy
print('\nTest accuracy:', test_acc)
আমরা দেখতে পাবো আমাদের মডেল প্রায় 97.45% একুরেসি দিচ্ছে।
প্রিডিকশন
# prediction img = x_test[0] img = np.array([img]) predictions = model.predict(img) # Print predicted number print(np.argmax(predictions)) # checking is it pridict correctly plt.imshow(x_test[0], cmap="gray") plt.show()
আমরা একটা সিঙ্গেল ইমেজ নিয়েছি প্রিডিক্ট করার জন্য। টেস্ট ডেটা প্রথম ইমেজটা নিয়েছি। আমাদের মডেল প্রিডিক্ট করেছে যে সংখ্যাটি 7। এবার টেস্ট ডেটার প্রথম ইমেজটি প্লট করে দেখলাম যে সংখ্যাটি 7। অর্থাৎ আমাদের মডেলটি সঠিক ভাবে প্রিডিক্ট করতে পেরেছে।
সম্পূর্ণ প্রজেক্ট – @ Google CoLab
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# import MNIST Handwritten-Digits dataset from the Keras library
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# checking is everything imported correctly
plt.imshow(x_train[0], cmap="gray")
plt.show()
print(x_train.shape)
print(x_test.shape)
# Normalize the train dataset
x_train = tf.keras.utils.normalize(x_train, axis=1)
# Normalize the test dataset
x_test = tf.keras.utils.normalize(x_test, axis=1)
# checking processed data
plt.imshow(x_train[0], cmap="gray")
plt.show()
# build the model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
# Compile the model
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# train the model
model.fit(x=x_train, y=y_train, epochs=5)
# Evaluate the model performance
test_loss, test_acc = model.evaluate(x=x_test, y=y_test)
# Print out the model accuracy
print('\nTest accuracy:', test_acc)
# pridction
img = x_test[0]
img = np.array([img])
predictions = model.predict(img)
# Print predicted number
print(np.argmax(predictions))
# checking is it pridict correctly
plt.imshow(x_test[0], cmap="gray")
plt.show()
মেশিন লার্নিং নিয়ে এই ব্লগে অনেক গুলো লেখা রয়েছে, সেগুলো পাওয়া যাবে আর্টিফিশিয়াল ইন্টিলিজেন্স এবং মেশিন লার্নিং পেইজে।
সব কিছু ঠিক মত করতে পারলে ক্যাগেলে গিয়ে Digit Recognizer কম্পিটিশনটাতে যতটুকু শিখেছেন, তা প্রয়োগ করে আসতে পারেন। ক্যাগেল সম্পর্কে বিস্তারিত জানতে এবং কিভাবে ক্যাগেলে কম্পিটিশন করতে হয়, তা জানা যাবে প্রথম পূর্নাঙ্গ মেশিন লার্নিং প্রজেক্ট ও ক্যাগেল কম্পিটেশন সাবমিশন লেখা থেকে।